library(gmodels)
library(factoextra)## Loading required package: ggplot2## Welcome! Want to learn more? See two factoextra-related books at https://goo.gl/ve3WBalibrary(FactoMineR)
library(ggplot2)
library(ggcorrplot)
library(psych)##
## Attaching package: 'psych'## The following objects are masked from 'package:ggplot2':
##
## %+%, alphalibrary(tidyverse)## ── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
## ✔ dplyr 1.1.2 ✔ readr 2.1.4
## ✔ forcats 1.0.0 ✔ stringr 1.5.0
## ✔ lubridate 1.9.2 ✔ tibble 3.2.1
## ✔ purrr 1.0.1 ✔ tidyr 1.3.0## ── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
## ✖ psych::%+%() masks ggplot2::%+%()
## ✖ psych::alpha() masks ggplot2::alpha()
## ✖ dplyr::filter() masks stats::filter()
## ✖ dplyr::lag() masks stats::lag()
## ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errorslibrary(outliers)##
## Attaching package: 'outliers'
##
## The following object is masked from 'package:psych':
##
## outlierlibrary(hrbrthemes)## NOTE: Either Arial Narrow or Roboto Condensed fonts are required to use these themes.
## Please use hrbrthemes::import_roboto_condensed() to install Roboto Condensed and
## if Arial Narrow is not on your system, please see https://bit.ly/arialnarrowlibrary(ggplot2)
library(dplyr)
library(plotly)##
## Attaching package: 'plotly'
##
## The following object is masked from 'package:ggplot2':
##
## last_plot
##
## The following object is masked from 'package:stats':
##
## filter
##
## The following object is masked from 'package:graphics':
##
## layoutlibrary(viridis)## Loading required package: viridisLitelibrary(hrbrthemes)
library(knitr)
library(kableExtra)##
## Attaching package: 'kableExtra'
##
## The following object is masked from 'package:dplyr':
##
## group_rowsFunções
Normalização MinMax
norm_minmax <- function(x){
(x- min(x)) /(max(x)-min(x))
}O que é segmentação de mercado?
Segmentação de mercado é o processo de divisão da base de clientes em vários grupos de indivíduos que compartilham uma semelhança de diferentes maneiras que são relevantes para o marketing, tais como sexo, idade, interesses e hábitos de gastos diversos.
As empresas que implantam a segmentação de clientes consideram que cada cliente tem requisitos diferentes e exigem um esforço de marketing específico para tratá-los adequadamente. As empresas visam obter uma abordagem mais profunda do cliente que estão almejando. Portanto, seu objetivo tem que ser específico e deve ser adaptado para atender às exigências individuais de cada cliente. Além disso, através dos dados coletados, as empresas podem obter uma compreensão mais profunda das preferências dos clientes, bem como os requisitos para descobrir segmentos valiosos que lhes proporcionariam o máximo lucro. Desta forma, elas podem estratificar suas técnicas de marketing de forma mais eficiente e minimizar a possibilidade de risco ao seu investimento.
A técnica de segmentação de clientes depende de vários diferenciais-chave que dividem os clientes em grupos a serem analisados. Dados relacionados à demografia, geografia, status econômico, bem como padrões comportamentais, desempenham um papel crucial na determinação da direção da empresa em direção aos vários segmentos.
Como implementar a segmentação de clientes no R?
Na primeira etapa deste projeto de ciência de dados, vamos realizar a exploração de dados. Importaremos os pacotes essenciais necessários para esta função e, em seguida, leremos nossos dados. Finalmente, analisaremos os dados de entrada para obter as informações necessárias.
mall_customers <- read_csv("D:/OneDrive - cefetmg.br/01_disciplinas/IntroR+business/03_atividades/2023/mall_customers.csv")
str(mall_customers)## spc_tbl_ [200 × 5] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
## $ customer_id : num [1:200] 1 2 3 4 5 6 7 8 9 10 ...
## $ gender : chr [1:200] "Male" "Male" "Female" "Female" ...
## $ age : num [1:200] 19 21 20 23 31 22 35 23 64 30 ...
## $ annual_income : num [1:200] 15 15 16 16 17 17 18 18 19 19 ...
## $ spending_score: num [1:200] 39 81 6 77 40 76 6 94 3 72 ...
## - attr(*, "spec")=
## .. cols(
## .. customer_id = col_double(),
## .. gender = col_character(),
## .. age = col_double(),
## .. annual_income = col_double(),
## .. spending_score = col_double()
## .. )
## - attr(*, "problems")=<externalptr>names(mall_customers)## [1] "customer_id" "gender" "age" "annual_income"
## [5] "spending_score"Temos uma variável que é uma identificação do consumidor, uma variável de gênero, uma de idade, outra de renda anual em k$ e um score de gastos que varia entre 1 e 100.
Vamos agora exibir as primeiras seis linhas de nosso conjunto de dados usando a função head() e usar a função summary() para emitir o seu resumo.
head(mall_customers)## # A tibble: 6 × 5
## customer_id gender age annual_income spending_score
## <dbl> <chr> <dbl> <dbl> <dbl>
## 1 1 Male 19 15 39
## 2 2 Male 21 15 81
## 3 3 Female 20 16 6
## 4 4 Female 23 16 77
## 5 5 Female 31 17 40
## 6 6 Female 22 17 76summary(mall_customers$gender)## Length Class Mode
## 200 character charactersummary(mall_customers$age)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 18.00 28.75 36.00 38.85 49.00 70.00summary(mall_customers$annual_income)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 15.00 41.50 61.50 60.56 78.00 137.00summary(mall_customers$spending_score)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 1.00 34.75 50.00 50.20 73.00 99.00Faça uma interpretação das variáveis
Visualização de gênero do cliente
Criaremos um barplot para mostrar a distribuição de gênero em nosso conjunto de dados de clientes_dados.
a <- table(mall_customers$gender)
ggplot(mall_customers, aes(x = gender)) +
geom_bar(fill="red") +
ggtitle("Usando o BarPlot para exibir a comparação de gênero") +
theme_ipsum() +
labs(x = "Gênero", y = "Número de ocorrências")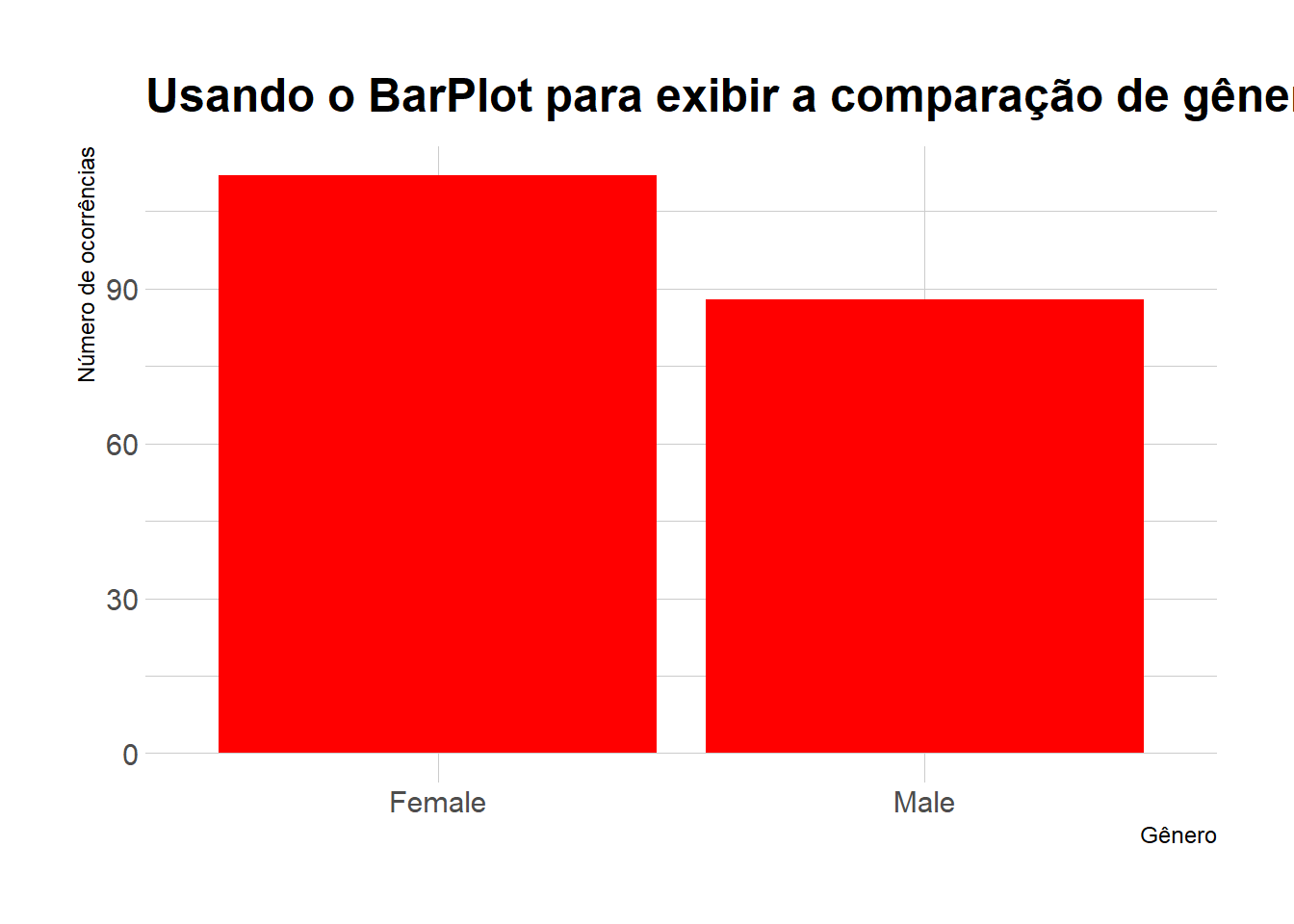
Pelo gráfico acima, observamos que o número de mulheres é maior do que o de homens.
Visualização da distribuição etária
Vamos traçar um histograma para visualizar a distribuição e traçar a freqüência das idades dos clientes. Primeiramente, procederemos com um resumo da variável Idade.
summary(mall_customers$age)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 18.00 28.75 36.00 38.85 49.00 70.00ggplot(mall_customers, aes(x = age)) +
geom_histogram(binwidth = 5) +
theme_ipsum() 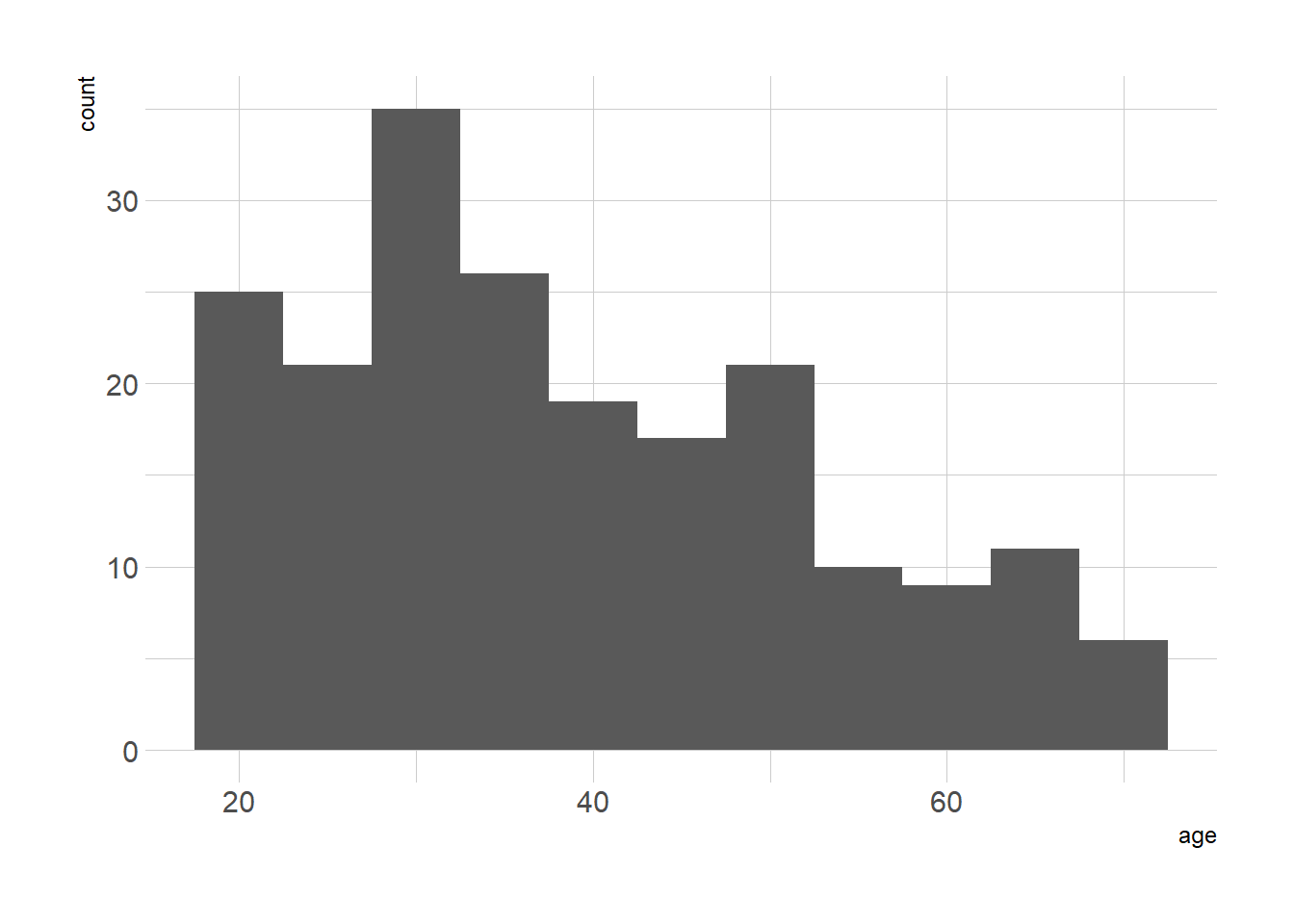
boxplot(mall_customers$age,
col="#ff0066",
main="Boxplot for Descriptive Analysis of Age")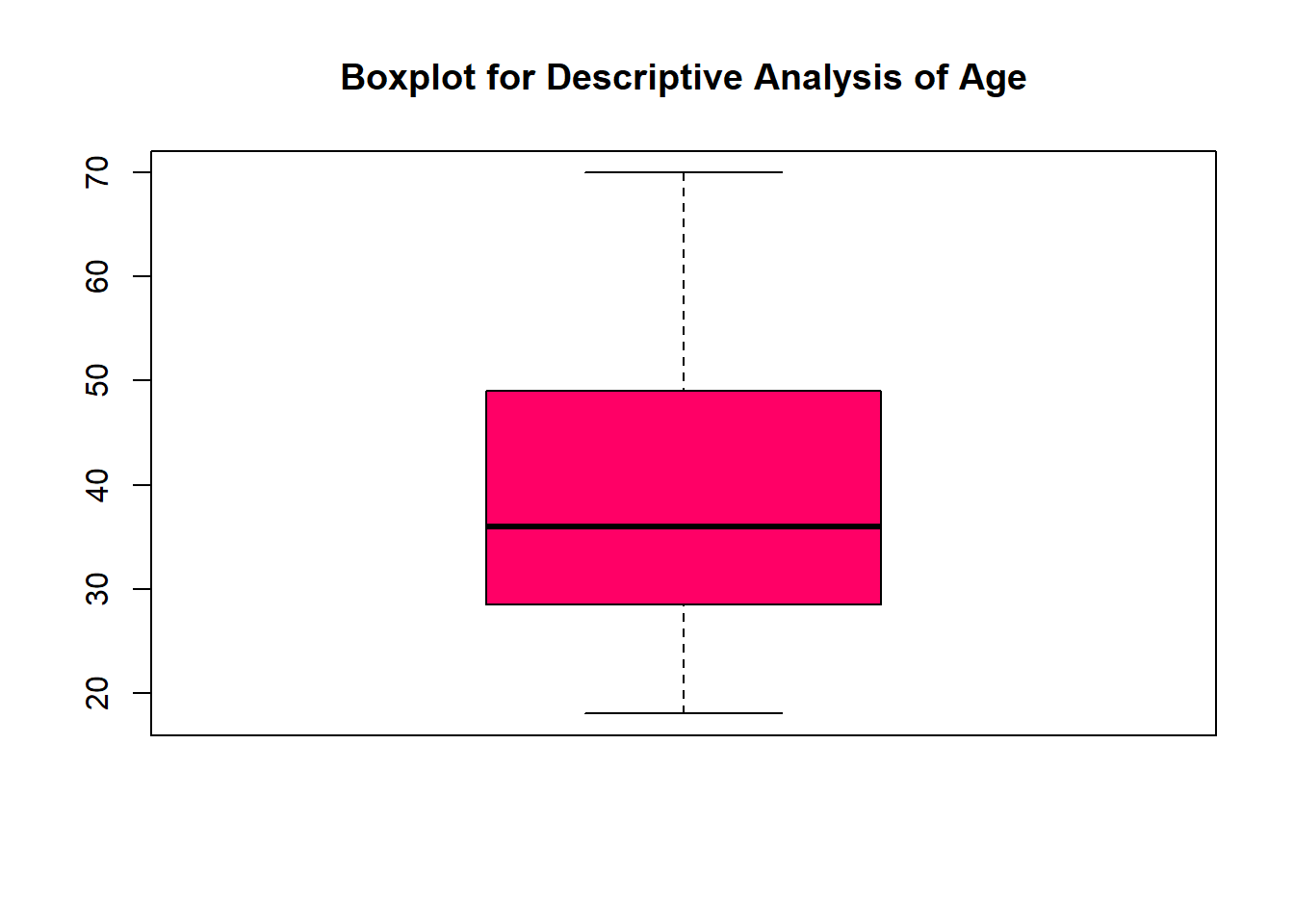
ggplot(mall_customers, aes(y = age)) +
geom_boxplot(fill="#ff0066") +
theme_ipsum() 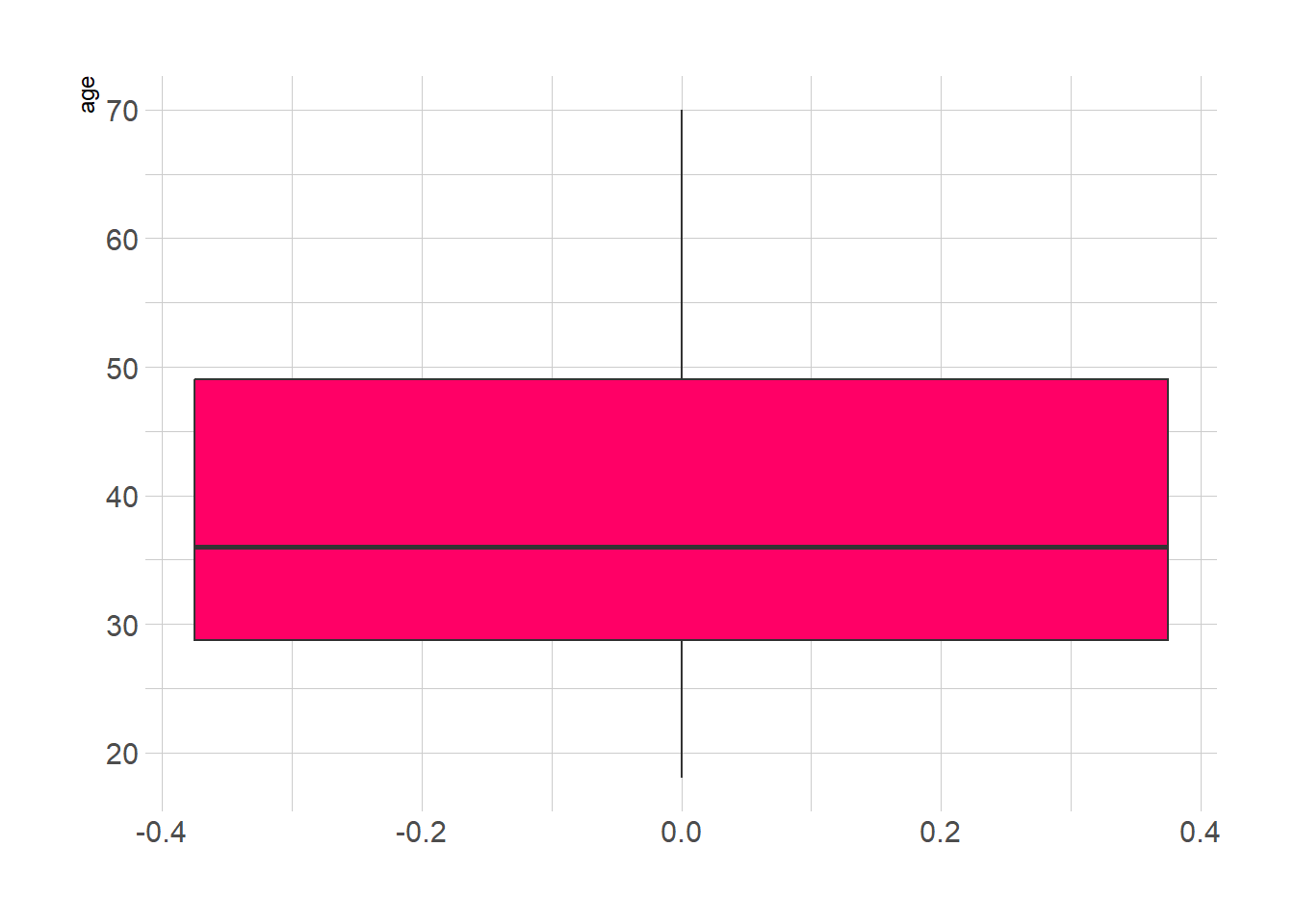
A partir das duas visualizações acima, concluímos que a idade mediana do cliente está entre 30 e 35 anos. A idade mínima dos clientes é 18 anos, enquanto que a idade máxima é 70 anos.
Análise da renda anual dos clientes
Nesta seção do projeto R, vamos criar visualizações para analisar a renda anual dos clientes. Traçaremos um histograma e então procederemos a examinar estes dados usando um gráfico de densidade.
summary(mall_customers$annual_income)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 15.00 41.50 61.50 60.56 78.00 137.00ggplot(mall_customers) +
geom_histogram(aes(x = annual_income), binwidth = 10, fill = "#660033") +
theme_ipsum() +
ggtitle("Histogram for Annual Income")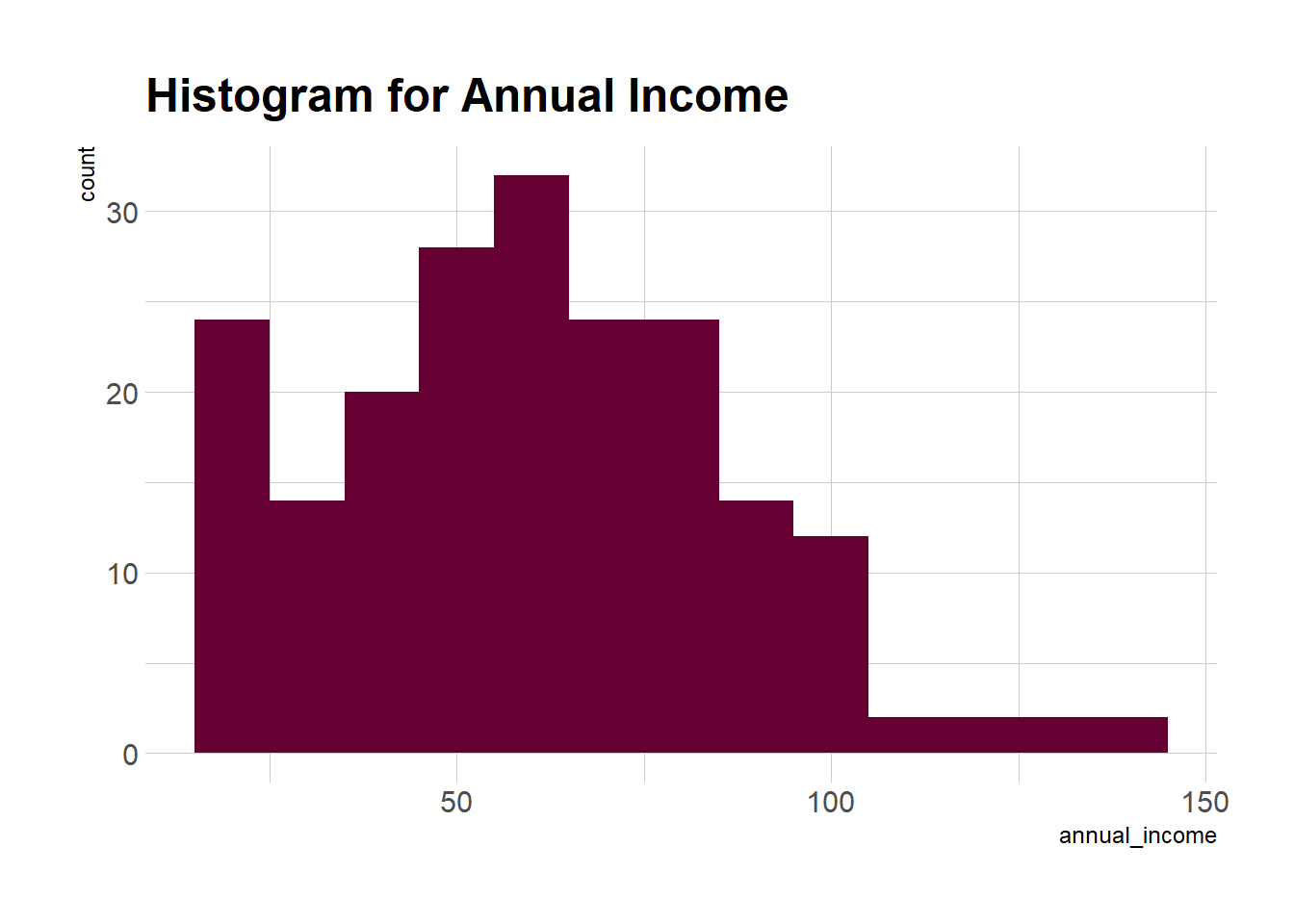
ggplot(mall_customers) +
geom_density(aes(x = annual_income), fill="#69b3a2", color="#e9ecef", alpha=0.8) +
theme_ipsum() +
ggtitle("Density for Annual Income")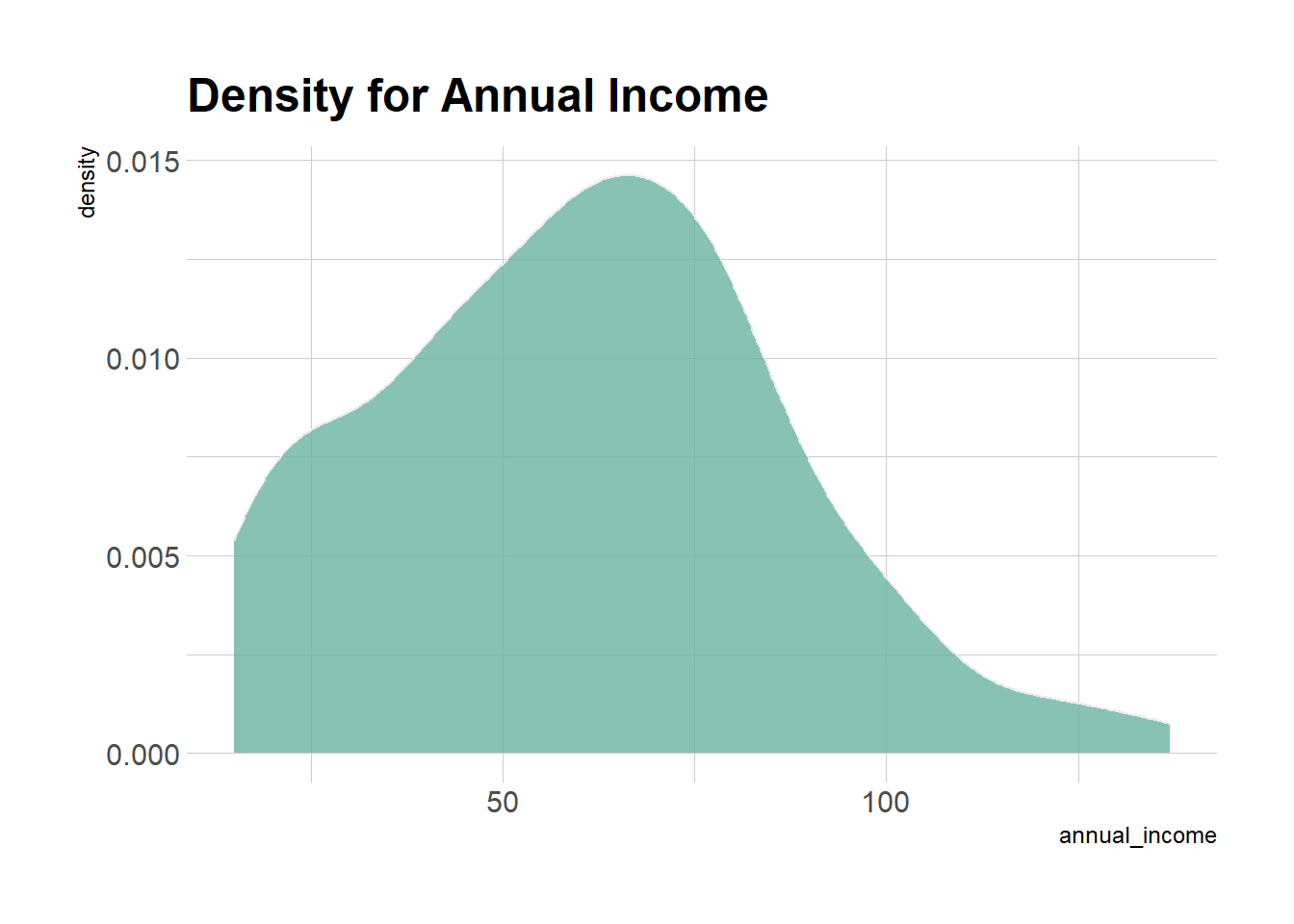
Da análise descritiva acima, concluímos que a renda mínima anual dos clientes é de 15 e a máxima renda é de 137 mil $ anuais. As pessoas que ganham uma renda média de 70 têm a maior contagem de freqüência em nossa distribuição de histogramas. O salário médio de todos os clientes é de 60,56.
Análise da pontuação de gastos dos clientes
summary(mall_customers$spending_score)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 1.00 34.75 50.00 50.20 73.00 99.00ggplot(mall_customers, aes(y = spending_score)) +
geom_boxplot(fill="#ff0066") +
theme_ipsum() 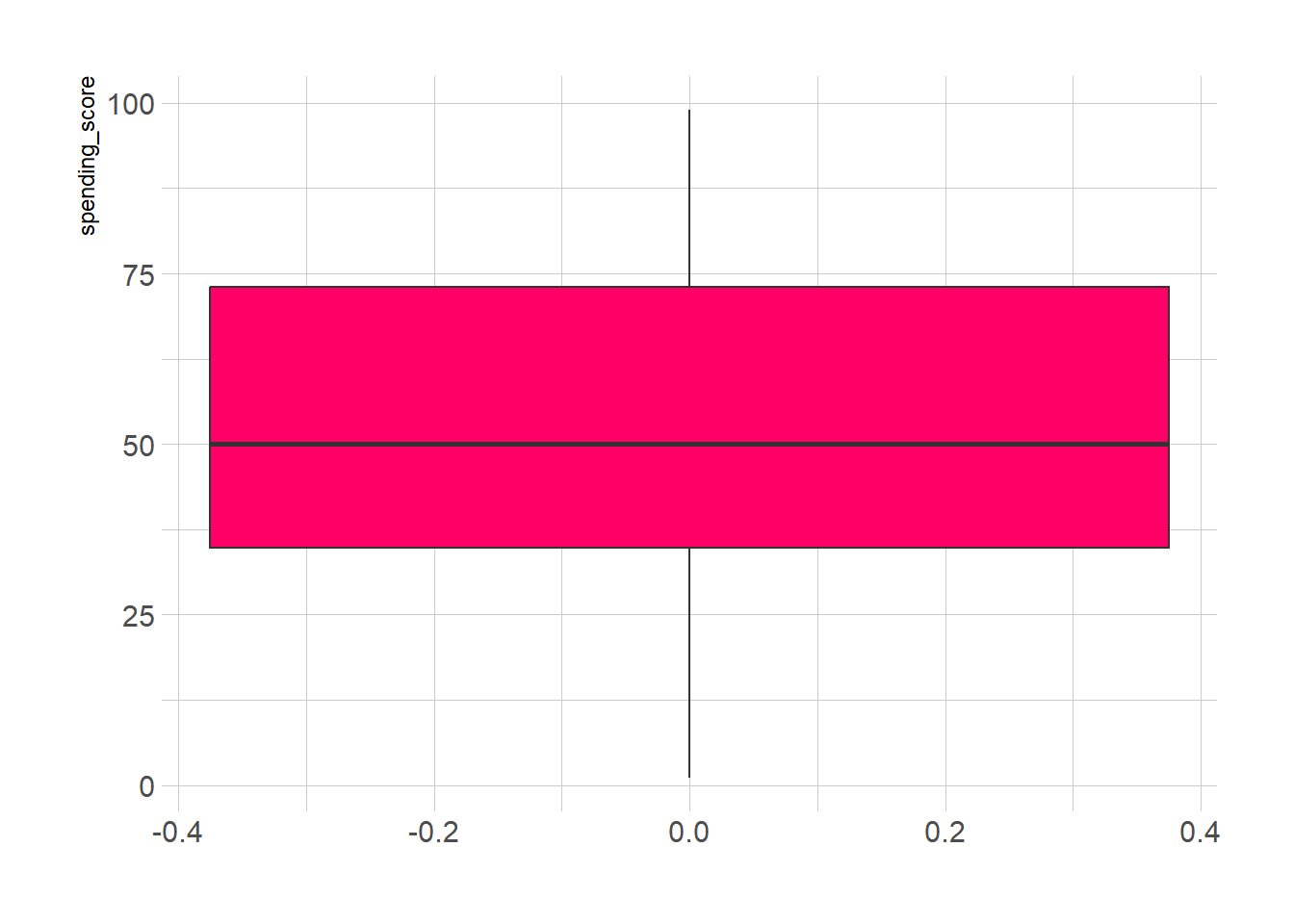
ggplot(mall_customers) +
geom_histogram(aes(x = spending_score), binwidth = 10, fill = "#660033") +
theme_ipsum() +
ggtitle("Histogram for Spending Score")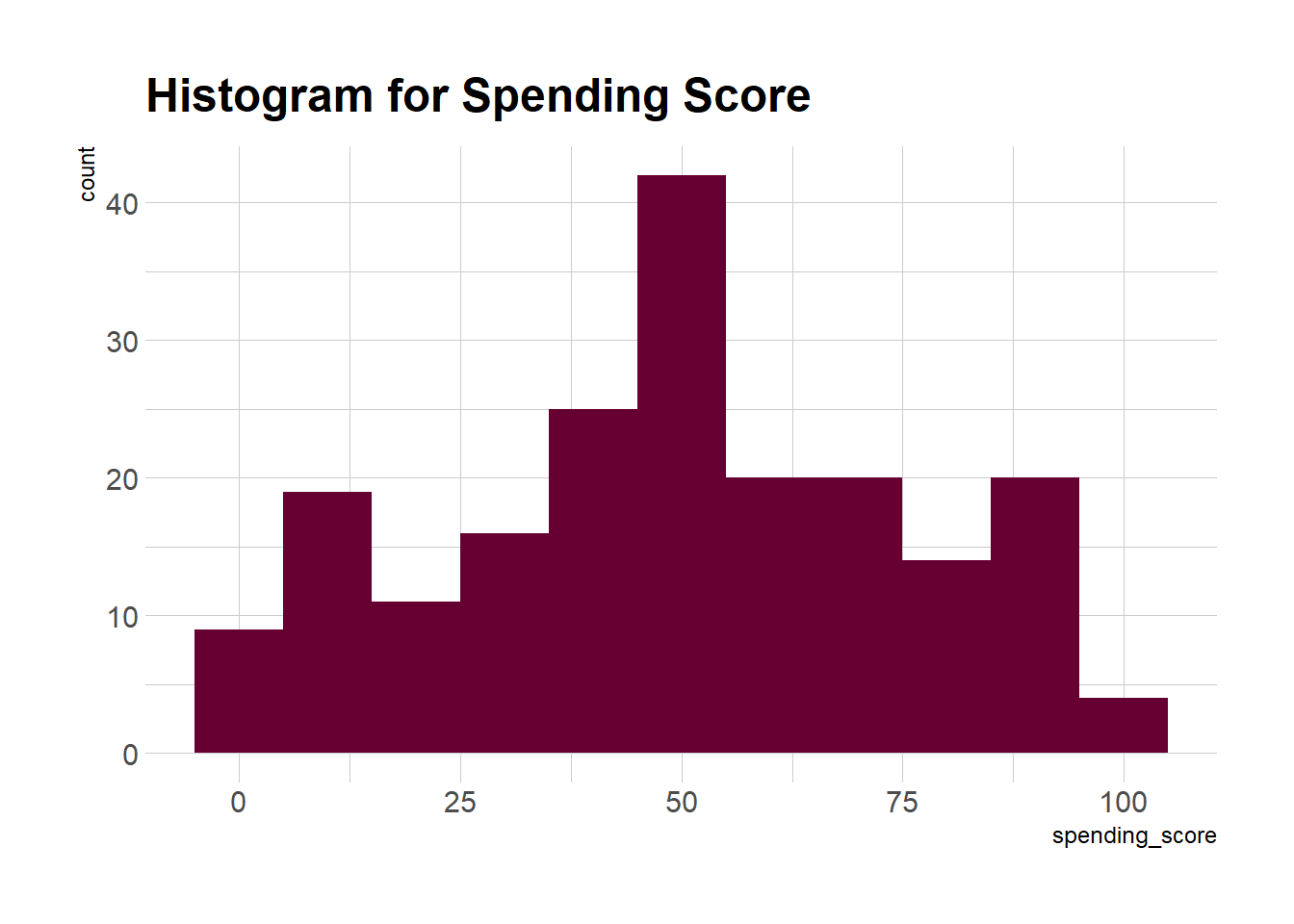
Podemos ver que a Análise Descritiva da Pontuação de Gastos é que Min é 1, Max é 99 e a média é 50,20. Pelo histograma, concluímos que os clientes entre as classes 40 e 50 são os mais frequentes entre todas as classes.
K-Means Cluster para segmentação de mercado
Ao utilizar o algoritmo K-Means clustering, o primeiro passo é indicar o número de clusters (k) que desejamos produzir. O algoritmo começa com a seleção aleatória de k objetos do conjunto de dados que servirão como os centros iniciais de nossos clusters.
Estes objetos selecionados são os meios de agrupamento, também conhecidos como centroides. Então, os objetos restantes são atribuídos aos centróides mais próximos. Esses centróides são definidos pela Distância Euclidiana presente entre o objeto e o cluster. Nos referimos a esta etapa como “atribuição de agrupamento”.
Quando a atribuição é concluída, o algoritmo procede para calcular o novo valor médio de cada agrupamento presente nos dados. Após o recálculo dos centros, as observações são verificadas, identificando se elas estão mais próximas de um agrupamento diferente. Usando a média atualizada do cluster, os objetos passam por uma reatribuição. Isto passa repetidamente por várias iterações até que as atribuições de agrupamento parem de se alterar. Os clusters que estão presentes na iteração atual são os mesmos que foram obtidos na iteração anterior.
Determinando o número de clusters ótimos
Ao trabalhar com clusters, é preciso especificar o número de clusters a serem utilizados. Para ajudá-lo a determinar os clusters ideais, há três métodos populares. Consideraremos o método de cotovelo.
O principal objetivo por trás de métodos de partição de clusters como o K-Means é definir os clusters de forma que a variação intra-cluster permaneça mínima.
No R, é possível implementar essa análise por meio da função a seguir.
df <- mall_customers %>%
mutate(gender = ifelse(gender == "Male", 1, 2)) %>%
select(gender, age, annual_income, spending_score)
fviz_nbclust(df, kmeans, method = "wss")+
geom_vline(xintercept = 6, linetype = 2)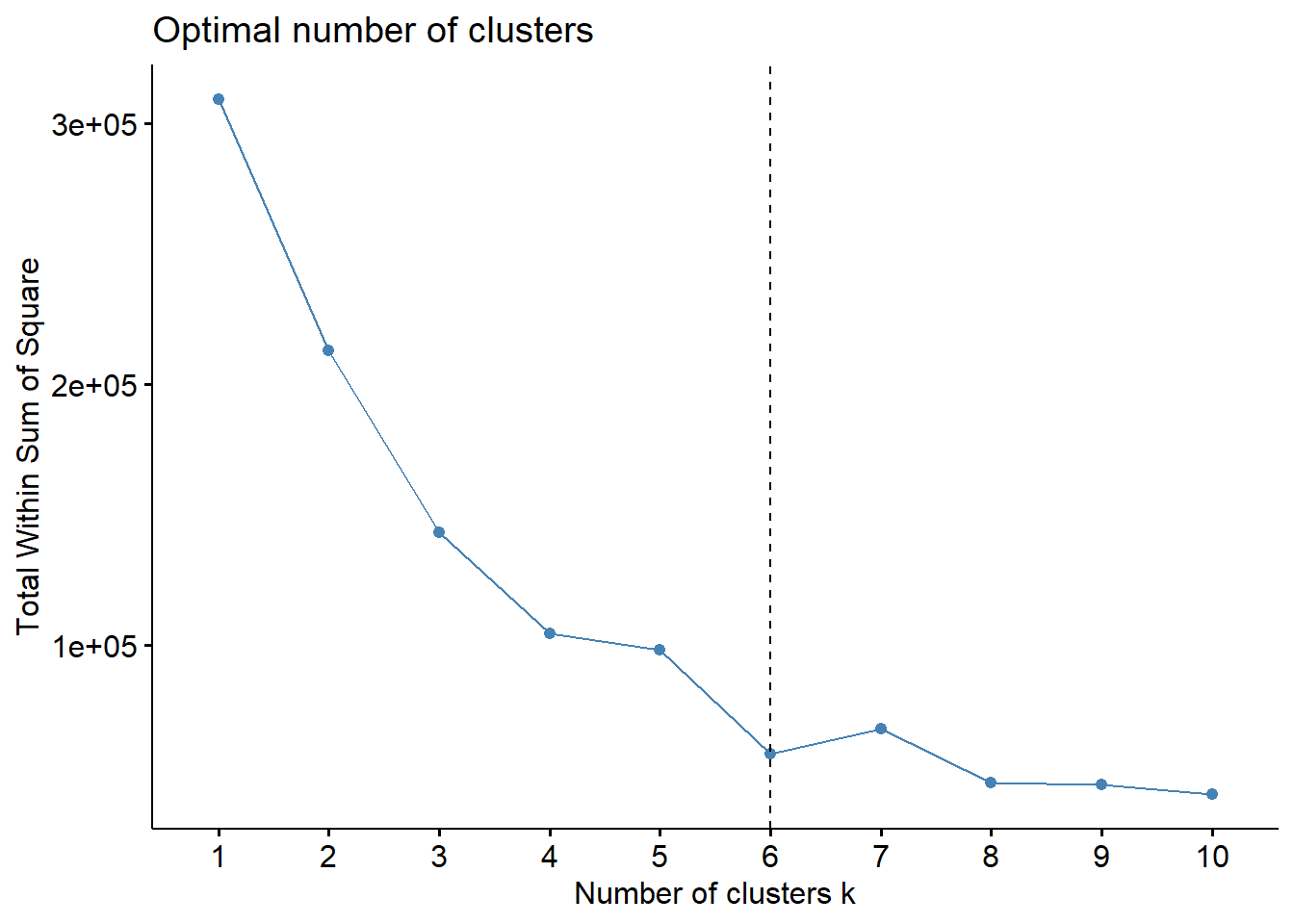
Do gráfico acima, concluímos que 6 é um número apropriado de clusters.
Usando a função fviz_nbclust(), é possível determinar e visualizar o número ideal de clusters por meio do método da silhueta:
library(NbClust)
library(factoextra)
fviz_nbclust(mall_customers[,3:5], kmeans, method = "silhouette")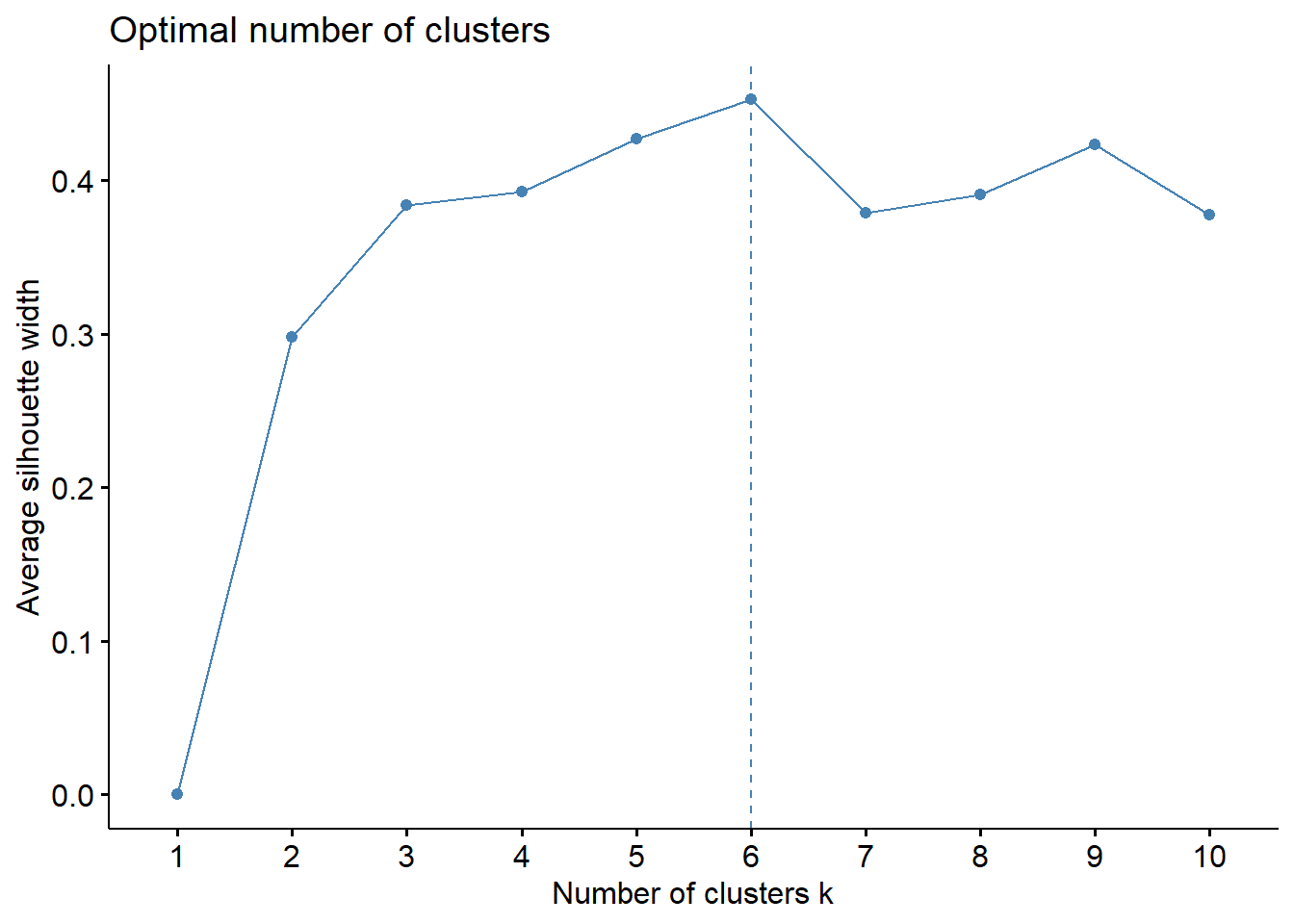
Agora, tomemos k = 6 como nosso número de clusters inicial.
set.seed(12345)
km.res <- kmeans(df, 6, nstart=25)
print(km.res)## K-means clustering with 6 clusters of sizes 39, 22, 35, 21, 38, 45
##
## Cluster means:
## gender age annual_income spending_score
## 1 1.538462 32.69231 86.53846 82.12821
## 2 1.590909 25.27273 25.72727 79.36364
## 3 1.428571 41.68571 88.22857 17.28571
## 4 1.619048 44.14286 25.14286 19.52381
## 5 1.657895 27.00000 56.65789 49.13158
## 6 1.555556 56.15556 53.37778 49.08889
##
## Clustering vector:
## [1] 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4
## [38] 2 4 2 6 2 6 5 4 2 6 5 5 5 6 5 5 6 6 6 6 6 5 6 6 5 6 6 6 5 6 6 5 5 6 6 6 6
## [75] 6 5 6 5 5 6 6 5 6 6 5 6 6 5 5 6 6 5 6 5 5 5 6 5 6 5 5 6 6 5 6 5 6 6 6 6 6
## [112] 5 5 5 5 5 6 6 6 6 5 5 5 1 5 1 3 1 3 1 3 1 5 1 3 1 3 1 3 1 3 1 5 1 3 1 3 1
## [149] 3 1 3 1 3 1 3 1 3 1 3 1 3 1 3 1 3 1 3 1 3 1 3 1 3 1 3 1 3 1 3 1 3 1 3 1 3
## [186] 1 3 1 3 1 3 1 3 1 3 1 3 1 3 1
##
## Within cluster sum of squares by cluster:
## [1] 13982.051 4105.136 16699.429 7737.333 7751.447 8073.244
## (between_SS / total_SS = 81.1 %)
##
## Available components:
##
## [1] "cluster" "centers" "totss" "withinss" "tot.withinss"
## [6] "betweenss" "size" "iter" "ifault"Na saída de nossa operação de kmeans, observamos uma lista com várias informações-chave. A partir daí, concluímos que as informações úteis são:
- cluster - Este é um vetor de vários inteiros que denotam o cluster que tem uma alocação de cada ponto.+
- totss - Isto representa a soma total dos quadrados.
- centers - Matriz composta por vários centros de agrupamento
- withinss - Este é um vetor que representa a soma intra-cluster dos quadrados tendo um componente por cluster.
- tot.withinss - Denota a soma total intra-cluster dos quadrados.
- betweenss - Esta é a soma dos quadrados entre os quadrados de um cluster.
- size - O número total de pontos que cada cluster possui.
As médias das variáveis para os agrupamentos podem ser obtidas por meio da função:
cluster_result <- aggregate(df, by=list(cluster=km.res$cluster), mean)
cluster_result## cluster gender age annual_income spending_score
## 1 1 1.538462 32.69231 86.53846 82.12821
## 2 2 1.590909 25.27273 25.72727 79.36364
## 3 3 1.428571 41.68571 88.22857 17.28571
## 4 4 1.619048 44.14286 25.14286 19.52381
## 5 5 1.657895 27.00000 56.65789 49.13158
## 6 6 1.555556 56.15556 53.37778 49.08889O conjunto de agrupamentos pode ser analisado por meio da função:
Relacionando as variáveis:
ggplot(df2, aes(x = annual_income, y = spending_score)) +
geom_point(stat = "identity", aes(color = as.factor(cluster))) +
scale_color_discrete(name=" ",
breaks=c("1", "2", "3", "4", "5","6"),
labels=c("Cluster 1", "Cluster 2", "Cluster 3", "Cluster 4", "Cluster 5","Cluster 6")) +
ggtitle("Segments of Mall Customers", subtitle = "Using K-means Clustering")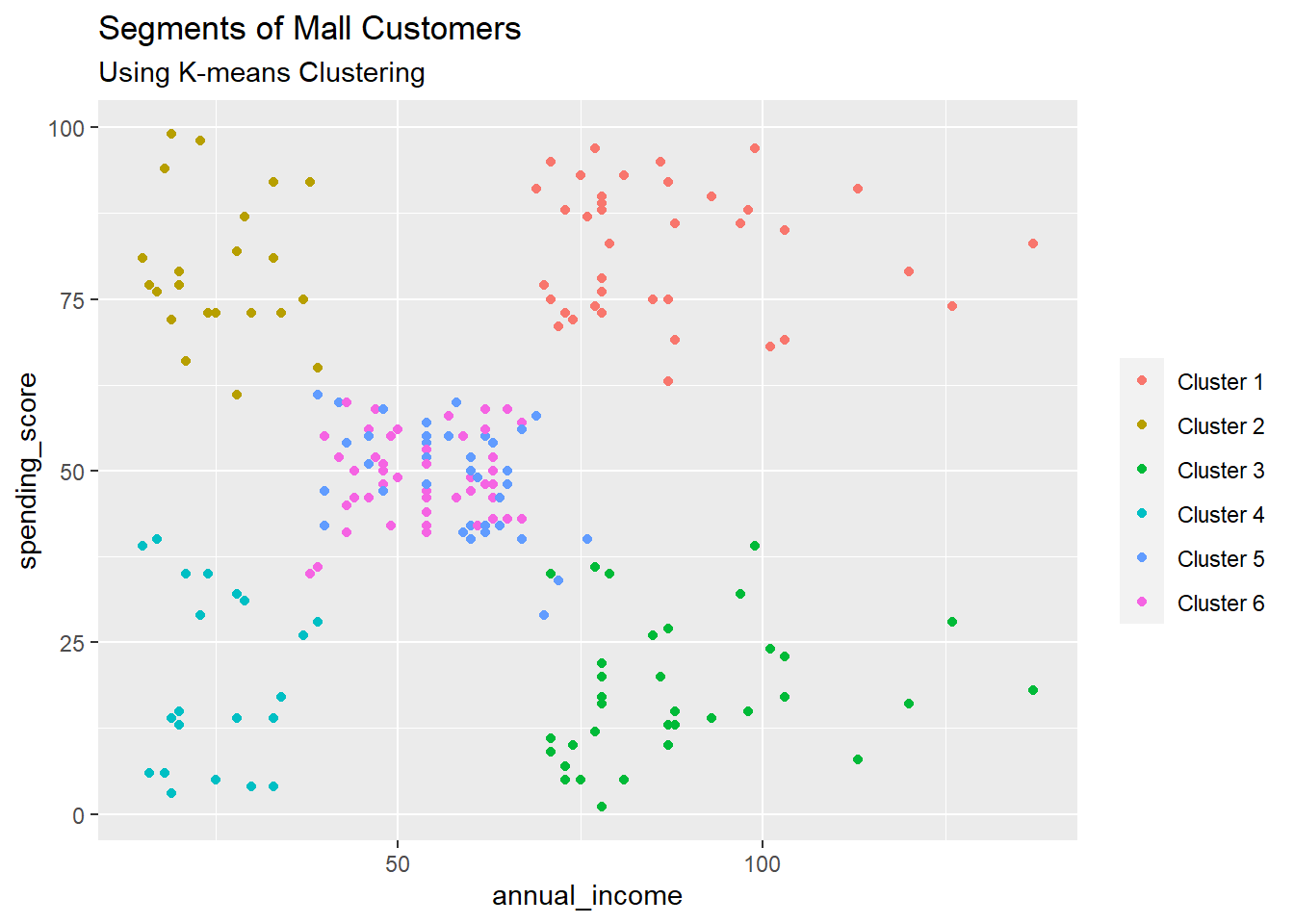
Complete a análise a seguir identificando os agrupamentos:
Da visualização acima, observamos que há uma distribuição de 6 clusters como segue:
Cluster ___ e ___ - Estes clusters representam os dados do cliente com o salário médio de renda, bem como o gasto médio anual de salário.
Cluster ___ - Este cluster representa o cliente_dados com uma alta renda anual, bem como um alto gasto anual.
Cluster ___ - Este grupo denota os dados do cliente com baixa renda anual, bem como o baixo gasto anual de renda.
Cluster ___ - Este cluster denota uma alta renda anual e um baixo gasto anual.
Cluster ___ - Este cluster representa uma baixa renda anual, mas seu alto gasto anual.
Com a ajuda do clustering, podemos compreender muito melhor as variáveis, o que nos leva a tomar decisões cuidadosas. Com a identificação dos clientes, as empresas podem lançar produtos e serviços que visam clientes com base em vários parâmetros como renda, idade, padrões de gastos, etc. Além disso, padrões mais complexos, como revisões de produtos, são levados em consideração para melhor segmentação.
Síntese
Neste projeto de ciência de dados, passamos pelo modelo de segmentação do cliente. Desenvolvemos isto por meio de um algoritmo de clustering chamado K-means clustering. Analisamos e visualizamos os dados e depois procedemos à implementação de nosso algoritmo.
Créditos1