Atividade
Nessa mini-análise trabalharemos com os dados usados no projeto publicada por Five Thirty Eight “The Dollar-And-Cents Case Against Hollywood’s Exclusion of Women”.
Sua tarefa é preencher os espaços em branco assinalados por ___.
Dados e pacotes
Vamos analisar o conjunto de dados bechdel, que contém informações sobre filmes e seu desempenho financeiro, além de informações sobre o teste de Bechdel, que avalia a representação feminina em filmes.
O teste de Bechdel é um critério simples que avalia se um filme contém pelo menos duas mulheres que falam entre si sobre algo que não seja um homem.
Começamos com o carregamento dos pacotes que vamos utilizar.
library(pacman)
p_load(fivethirtyeight, tidyverse, tidytuesday)## Warning: package 'tidytuesday' is not available for this version of R
##
## A version of this package for your version of R might be available elsewhere,
## see the ideas at
## https://cran.r-project.org/doc/manuals/r-patched/R-admin.html#Installing-packages## Warning: 'BiocManager' not available. Could not check Bioconductor.
##
## Please use `install.packages('BiocManager')` and then retry.## Warning in p_install(package, character.only = TRUE, ...):## Warning in library(package, lib.loc = lib.loc, character.only = TRUE,
## logical.return = TRUE, : there is no package called 'tidytuesday'## Warning in p_load(fivethirtyeight, tidyverse, tidytuesday): Failed to install/load:
## tidytuesdayO carregamento dos dados pode ser feito considerando o código a seguir:
raw_bechdel <- readr::read_csv('https://raw.githubusercontent.com/rfordatascience/tidytuesday/main/data/2021/2021-03-09/raw_bechdel.csv')## Rows: 8839 Columns: 5
## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: ","
## chr (2): imdb_id, title
## dbl (3): year, id, rating
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.movies <- readr::read_csv('https://raw.githubusercontent.com/rfordatascience/tidytuesday/main/data/2021/2021-03-09/movies.csv')## Rows: 1794 Columns: 34
## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: ","
## chr (24): imdb, title, test, clean_test, binary, domgross, intgross, code, d...
## dbl (7): year, budget, budget_2013, period_code, decade_code, metascore, im...
## num (1): imdb_votes
## lgl (2): response, error
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.raw_bechdel.csv
| variável | tipo de dado | descrição |
|---|---|---|
| year | integer | Year of release |
| id | integer | ID of film |
| imdb_id | character | IMDB ID |
| title | character | Title of film |
| rating | integer | Rating (0-3), 0 = unscored, 1. It has to have at least two [named] women in it, 2. Who talk to each other, 3. About something besides a man |
movies.csv
| Variável | Tipo de dado | Descrição |
|---|---|---|
| year | double | Year |
| imdb | character | IMDB |
| title | character | Title of movie |
| test | character | Bechdel Test outcome |
| clean_test | character | Bechdel Test cleaned |
| binary | character | Binary pass/fail of bechdel |
| budget | double | Budget as of release year |
| domgross | character | Domestic gross in release year |
| intgross | character | International gross in release year |
| code | character | Code |
| budget_2013 | double | Budget normalized to 2013 |
| domgross_2013 | character | Domestic gross normalized to 2013 |
| intgross_2013 | character | International gross normalized to 2013 |
| period_code | double | Period code |
| decade_code | double | Decade Code |
| imdb_id | character | IMDB ID |
| plot | character | Plot of movie |
| rated | character | Rating of movie |
| response | character | Response? |
| language | character | Language of film |
| country | character | Country produced in |
| writer | character | Writer of film |
| metascore | double | Metascore rating (0-100) |
| imdb_rating | double | IMDB Rating 0-10 |
| director | character | Director of movie |
| released | character | Released date |
| actors | character | Actors |
| genre | character | Genre |
| awards | character | Awards |
| runtime | character | Runtime |
| type | character | Type of film |
| poster | character | Poster image |
| imdb_votes | character | IMDB Votes |
| error | character | Error? |
Vamos focar nossa análise em filmes lançados entre 1990 e 2013.
bechdel90_13 <- bechdel %>%
filter(between(year, 1990, 2013))Existem ’___’ filmes. (insira a quantidade de filmes)
As variáveis financeiras em que vamos nos concentrar são as seguintes:
budget_2013: Orçamento em dólares de 2013 ajustados à inflação.domgross_2013: Dólares internos brutos (EUA) em 2013, dólares ajustados pela inflação.intgross_2013: Total internacional (i.e., mundial) bruto em 2013 dólares corrigidos da inflação.
E também utilizaremos as variáveis binary e clean_test para grouping.
Análise
Vamos ver como o orçamento mediano e o bruto variam conforme o filme caso tenha passado no teste de Bechdel, que é armazenado na variável “binary”.
bechdel90_13 %>%
group_by(binary) %>%
summarise(med_budget = median(budget_2013),
med_domgross = median(domgross_2013, na.rm = TRUE),
med_intgross = median(intgross_2013, na.rm = TRUE))## # A tibble: 2 × 4
## binary med_budget med_domgross med_intgross
## <chr> <dbl> <dbl> <dbl>
## 1 FAIL 48385984. 57318606. 104475669
## 2 PASS 31070724 45330446. 80124349Em seguida, vamos ver como o orçamento meidano e o bruto variam por um indicador mais detalhado do resultado do teste de Bechdel.
Essa informação é armazenada na variável ‘clean_test’, que assume os seguintes valores:
ok= passa no testedubious.men= as mulheres só falam de homensnotalk= as mulheres não falam umas com as outrasnowomen= menos de duas mulheres
bechdel90_13 %>%
group_by(clean_test) %>%
summarise(med_budget = median(budget_2013),
med_domgross = median(domgross_2013, na.rm = TRUE),
med_intgross = median(intgross_2013, na.rm = TRUE))## # A tibble: 5 × 4
## clean_test med_budget med_domgross med_intgross
## <ord> <dbl> <dbl> <dbl>
## 1 nowomen 43373066 44891296. 89509349
## 2 notalk 56570084. 63890455 123102194
## 3 men 39737690. 56392786 99578022.
## 4 dubious 35790994 49173429 89883201
## 5 ok 31070724 45330446. 80124349A fim de avaliar como o retorno do investimento varia entre os filmes que passam e fracassam no teste de Bechdel, vamos primeiro criar uma nova variável chamada roi como uma razão do orçamento bruto.
bechdel90_13 <- bechdel90_13 %>%
mutate(roi = (intgross_2013 + domgross_2013) / budget_2013)Vamos ver quais filmes têm o maior retorno sobre o investimento.
bechdel90_13 %>%
arrange(desc(roi)) %>%
select(title, roi, year)## # A tibble: 1,615 × 3
## title roi year
## <chr> <dbl> <int>
## 1 Paranormal Activity 671. 2007
## 2 The Blair Witch Project 648. 1999
## 3 El Mariachi 583. 1992
## 4 Clerks. 258. 1994
## 5 In the Company of Men 231. 1997
## 6 Napoleon Dynamite 227. 2004
## 7 Once 190. 2006
## 8 The Devil Inside 155. 2012
## 9 Primer 142. 2004
## 10 Fireproof 134. 2008
## # ℹ 1,605 more rowsAbaixo está uma visualização do retorno do investimento por resultado de teste, porém é difícil ver as distribuições devido a algumas observações extremas.
ggplot(data = bechdel90_13,
mapping = aes(x = clean_test, y = roi, color = binary)) +
geom_boxplot() +
labs(title = "Retorno do investimento vs. Resultados do teste Bechdel",
x = "Resultado detalhado de Bechdel",
y = "___",
color = "Resultado binário de Bechdel")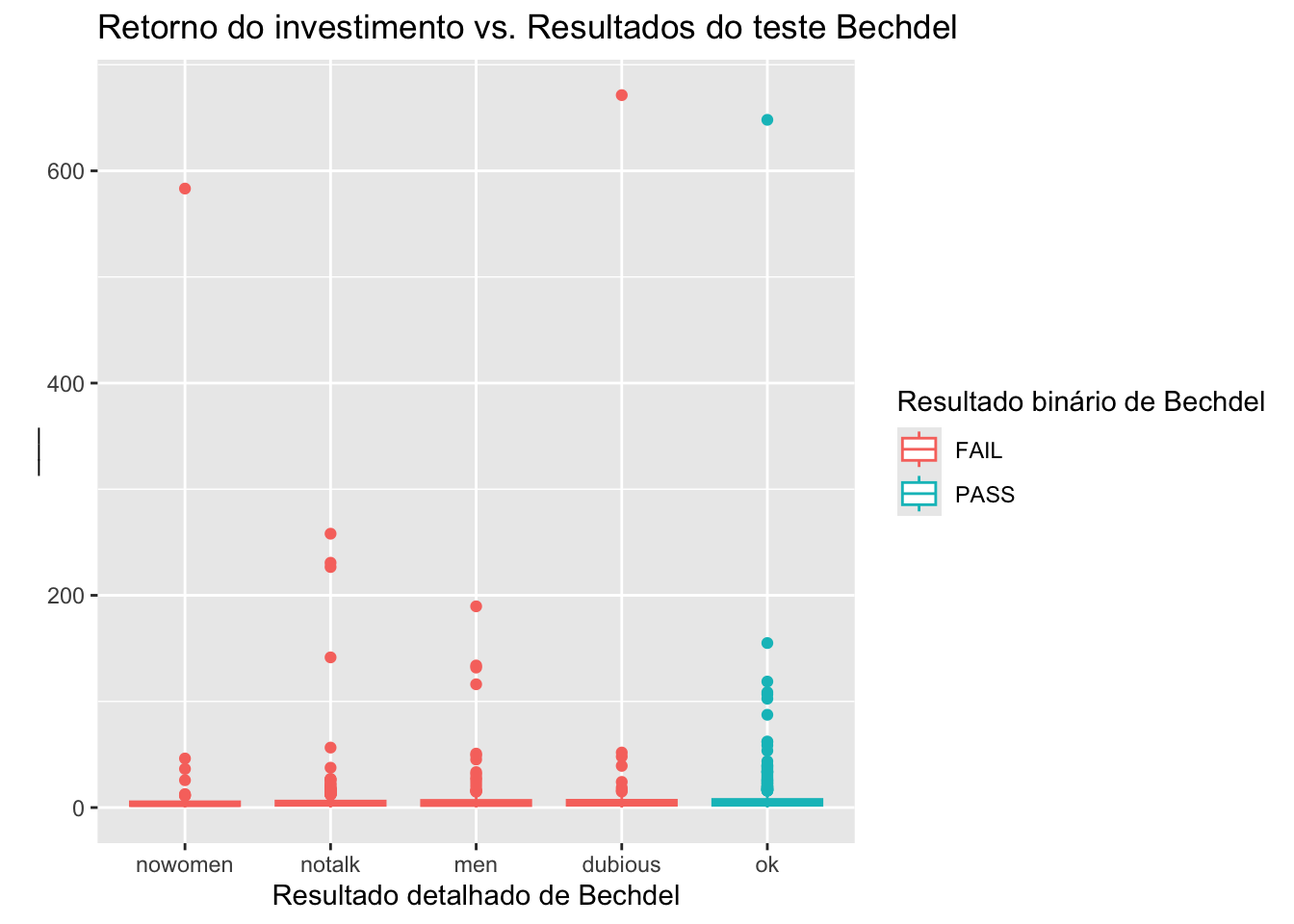
Quais são os filmes com retorno de investimento muito altos?
bechdel90_13 %>%
filter(roi > 400) %>%
select(title, budget_2013, domgross_2013, year)## # A tibble: 3 × 4
## title budget_2013 domgross_2013 year
## <chr> <int> <dbl> <int>
## 1 Paranormal Activity 505595 121251476 2007
## 2 The Blair Witch Project 839077 196538593 1999
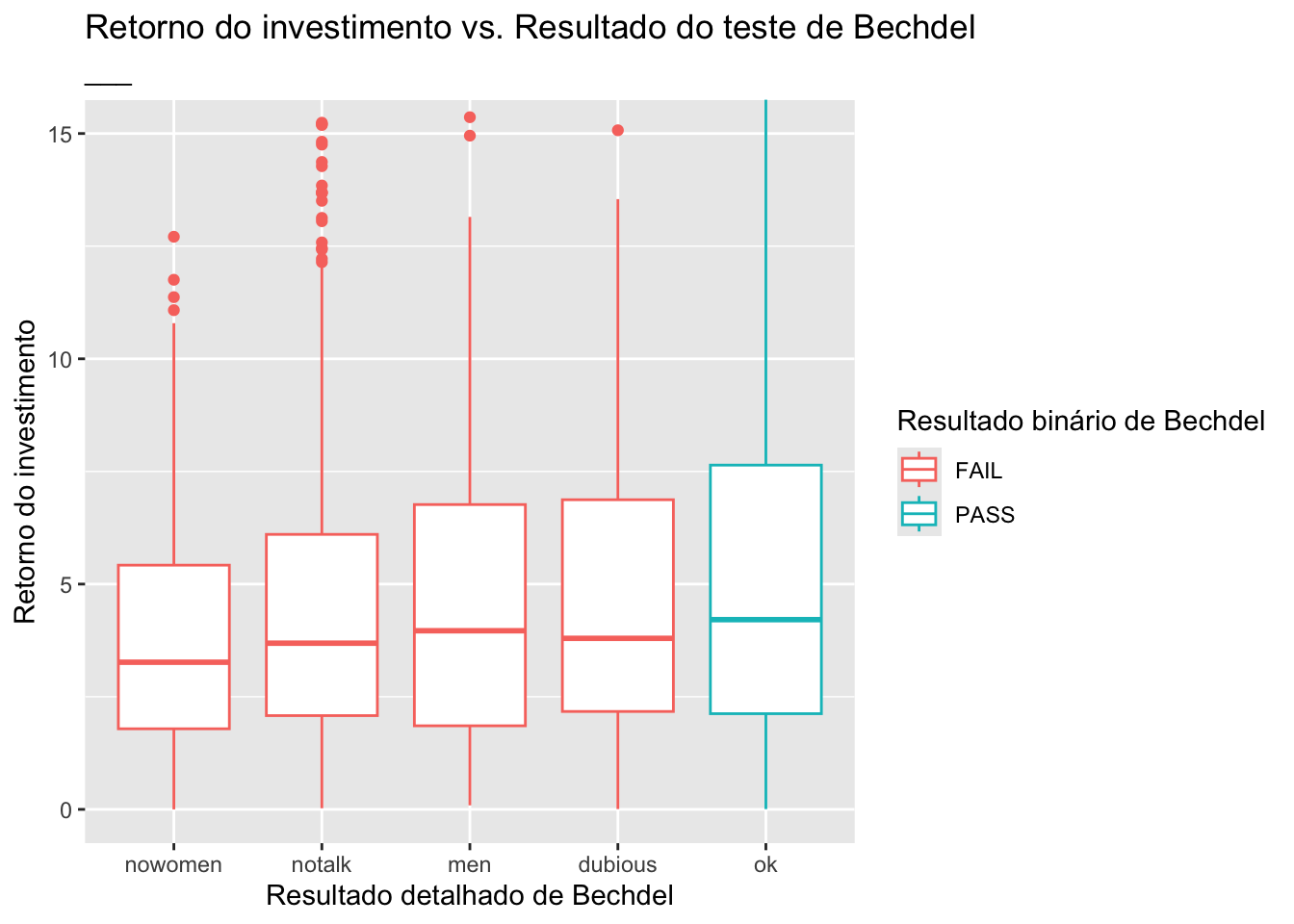
## 3 El Mariachi 11622 3388636 1992Veja como é a relação entre os filmes com menor retorno e o resultado detalhado do teste Bechedel.
A ampliação dos filmes com roi < ___ proporciona uma melhor visão de como os medianos através das categorias se comparam:
ggplot(data = bechdel90_13, mapping = aes(x = clean_test, y = roi, color = binary)) +
geom_boxplot() +
labs(title = "Retorno do investimento vs. Resultado do teste de Bechdel",
subtitle = "___", # Something about zooming in to a certain level
x = "Resultado detalhado de Bechdel",
y = "Retorno do investimento",
color = "Resultado binário de Bechdel") +
coord_cartesian(ylim = c(0, 15))