ANÁLISE ESPACIAL
library(aspace)
library(sf)
library(tmap)
library(cluster)
library(geosphere)
library(sp)Proximidade x similaridade
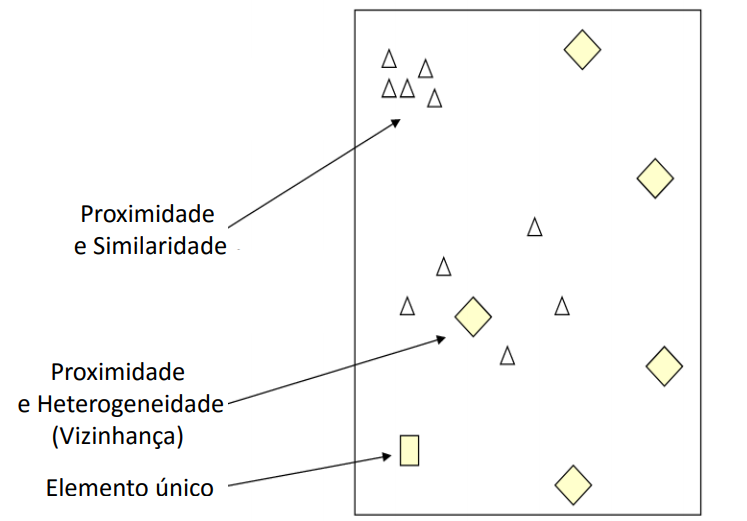
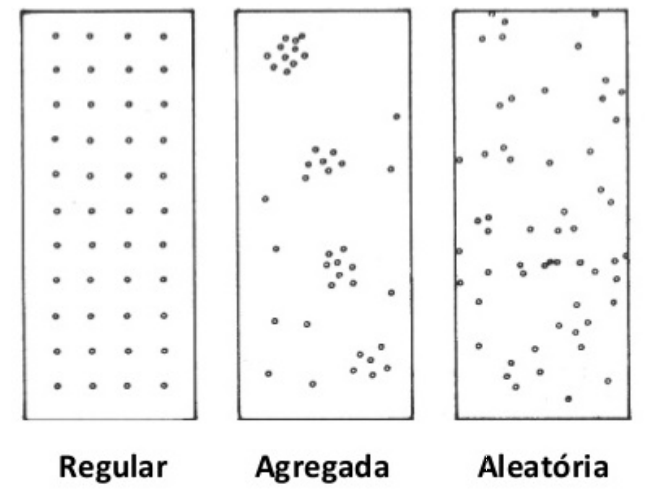
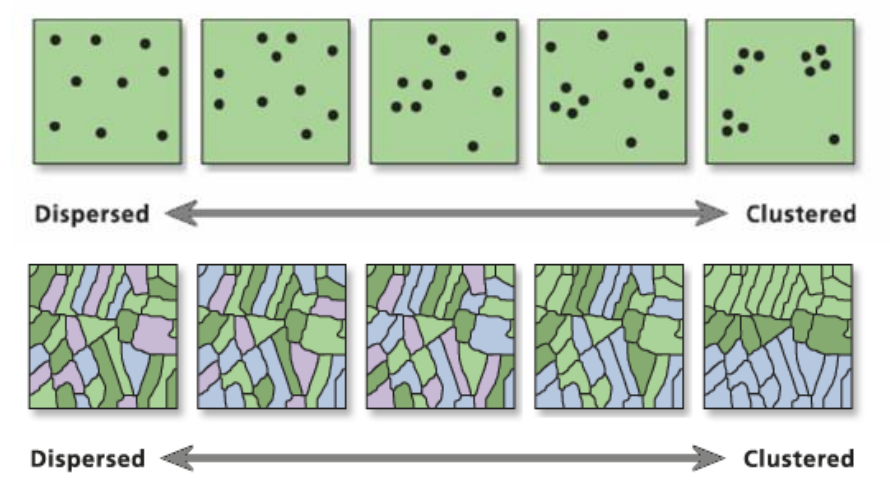
Padrões espaciais
Medidas centrográficas
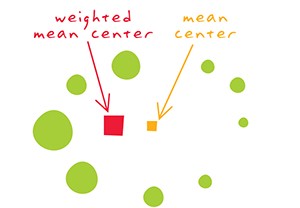
Centro Médio
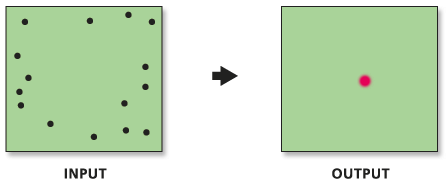
Distância Padrão
Aplicações
Medidas centrográficas no R
data <- read_sf("./shapefiles/ESCOLAS_PARTICULARES.shp")
bh <- read_sf("./shapefiles/BAIRRO.shp")
data_sp <- as_Spatial(data)tm_shape(data) +
tm_dots(size = 1.5, col = "grey40", alpha = 0.3) +
tm_shape(bh) +
tm_borders(col = "grey40", lwd = 1, lty = "solid", alpha = 0.3)
plot(data_sp)
Organização dos dados para cálculo do centro Médio e distância padrão
xy <- st_coordinates(data) # arquivo para calculos centrográficos
xy_coord <- as.data.frame(st_coordinates(data)) %>%
st_as_sf(coords = c('X', 'Y'), crs = 31983) # conversão em sf para representação espacial de coordenadas como pontoscálculo do centro Médio, distância padrão e elipse deviational
mc <- mean_centre(filename="mean_center.txt", weighted=FALSE, weights=NULL, points=xy)## id CENTRE.x CENTRE.y
## 1 1 608734 7798997mc_sd <- calc_sdd(filename="SDD_Output.txt", centre.xy=NULL, calccentre=TRUE, weighted=FALSE, weights=NULL, points=xy, verbose=FALSE) ## $id
## [1] 1
##
## $calccentre
## [1] TRUE
##
## $weighted
## [1] FALSE
##
## $CENTRE.x
## [1] 608734
##
## $CENTRE.y
## [1] 7798997
##
## $SDD.radius
## [1] 6927.293
##
## $SDD.area
## [1] 150756836# usar xy - Retorna um dataframe com o centro médio e a distância padrão - raio.
# Create the plot but don't show the markers
# Calculate and plot the first standard deviational ellipse on the existing plot
mc_se <- calc_sde(id = 1, filename="SDE_Output.txt", calccentre = TRUE, points = xy, verbose = TRUE);##
## ----------------------------------------------
## Coordinates of centre (x): 608734
## Coordinates of centre (y): 7798997
## Angle of rotation: 13.58 clockwise degrees
## Length of X axis: 10251.8
## Length of Y axis: 16697.3
## Area of SDE ellipse: 134442355
## tantheta: 0.2415669
## theta: 13.58059
## sintheta: 0.2348128
## costheta: 0.9720406
## sinthetacostheta: 0.2282476
## sin2theta: 0.05513706
## cos2theta: 0.9448629
## sigmax: 5125.899
## sigmay: 8348.649
## eccentricity: 0.789322
## ----------------------------------------------
##
## $id
## [1] 1
##
## $CALCCENTRE
## [1] TRUE
##
## $weighted
## [1] FALSE
##
## $CENTRE.x
## [1] 608734
##
## $CENTRE.y
## [1] 7798997
##
## $Sigma.x
## [1] 5125.899
##
## $Sigma.y
## [1] 8348.649
##
## $Major
## [1] "SigmaY"
##
## $Minor
## [1] "SigmaX"
##
## $Theta
## [1] 13.58059
##
## $Eccentricity
## [1] 0.789322
##
## $Area.sde
## [1] 134442355
##
## $TanTheta
## [1] 0.2415669
##
## $SinTheta
## [1] 0.2348128
##
## $CosTheta
## [1] 0.9720406
##
## $SinThetaCosTheta
## [1] 0.2282476
##
## $Sin2Theta
## [1] 0.05513706
##
## $Cos2Theta
## [1] 0.9448629
##
## $ThetaCorr
## [1] 13.58059### SDD plot
plot_sdd(plotnew=TRUE, plotcentre=FALSE, centre.col="red", centre.pch="1", sdd.col="red",sdd.lwd=1,titletxt="", plotpoints=TRUE, points.col="black")
# Label the centroid, explicitly using the hidden r.SDD object that was used in plot_sde
text(r.SDD$CENTRE.x, r.SDD$CENTRE.y, "+", col="red")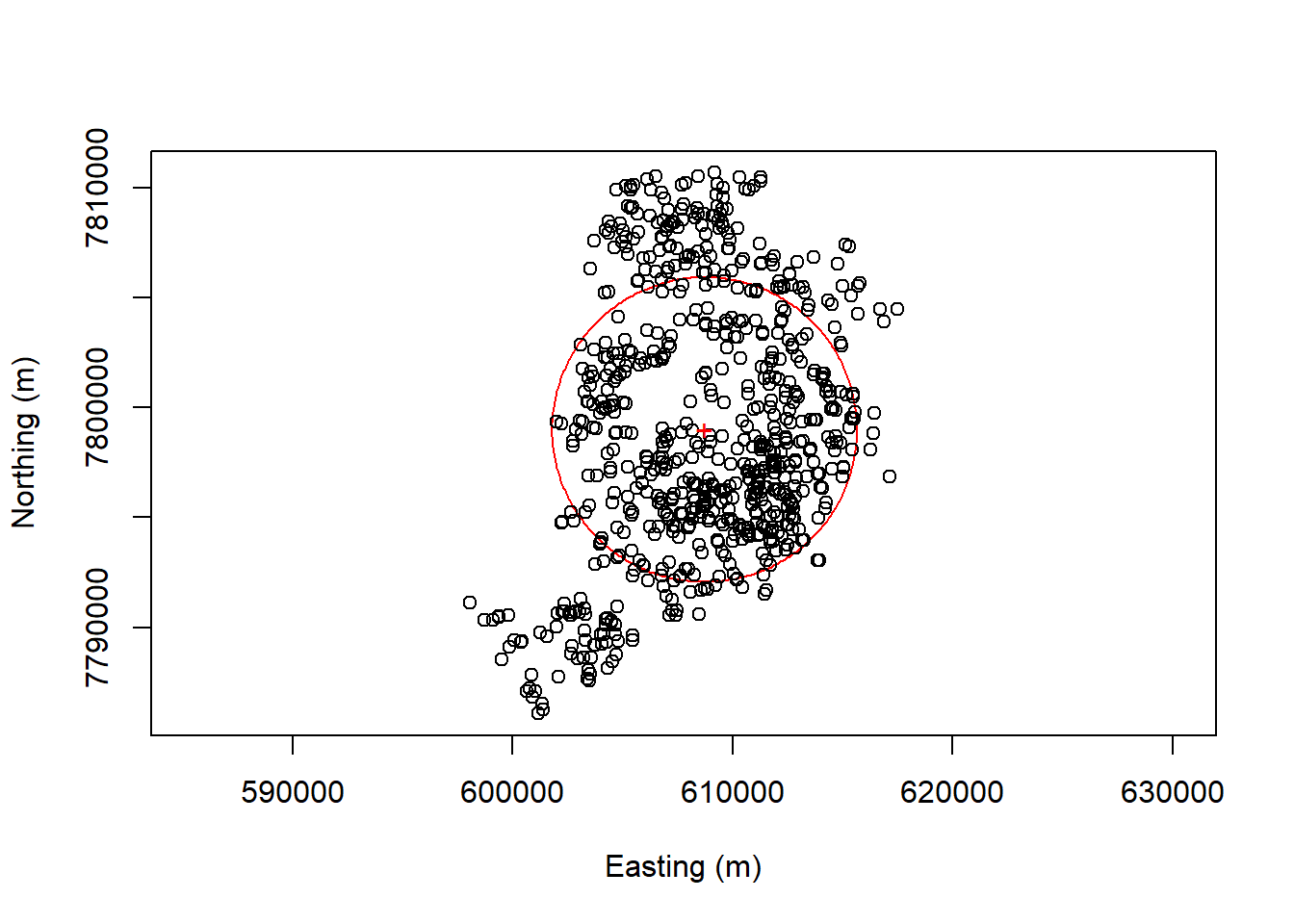
## plot_sdd by default takes as input the result produced from the calc_sdd, read from the current workspace.
## SDD to shapefile
shp_sdd <- convert.to.shapefile(sddloc,sddatt,"id",5)
write.shapefile(shp_sdd, "shapefiles/SDD_Shape", arcgis=T)
## SDE to shapefile
shp_sde <- convert.to.shapefile(sdeloc,sdeatt,"id",5)
write.shapefile(shp_sde, "shapefiles/SDE_Shape", arcgis=T)plot_sde(plotnew=TRUE, plotcentre=FALSE, centre.col="red", centre.pch="1", sde.col="red",sde.lwd=1,titletxt="", plotpoints=TRUE,points.col="black")
# Label the centroid, explicitly using the hidden r.SDE object that was used in plot_sde
text(r.SDE$CENTRE.x, r.SDE$CENTRE.y, "+", col="red")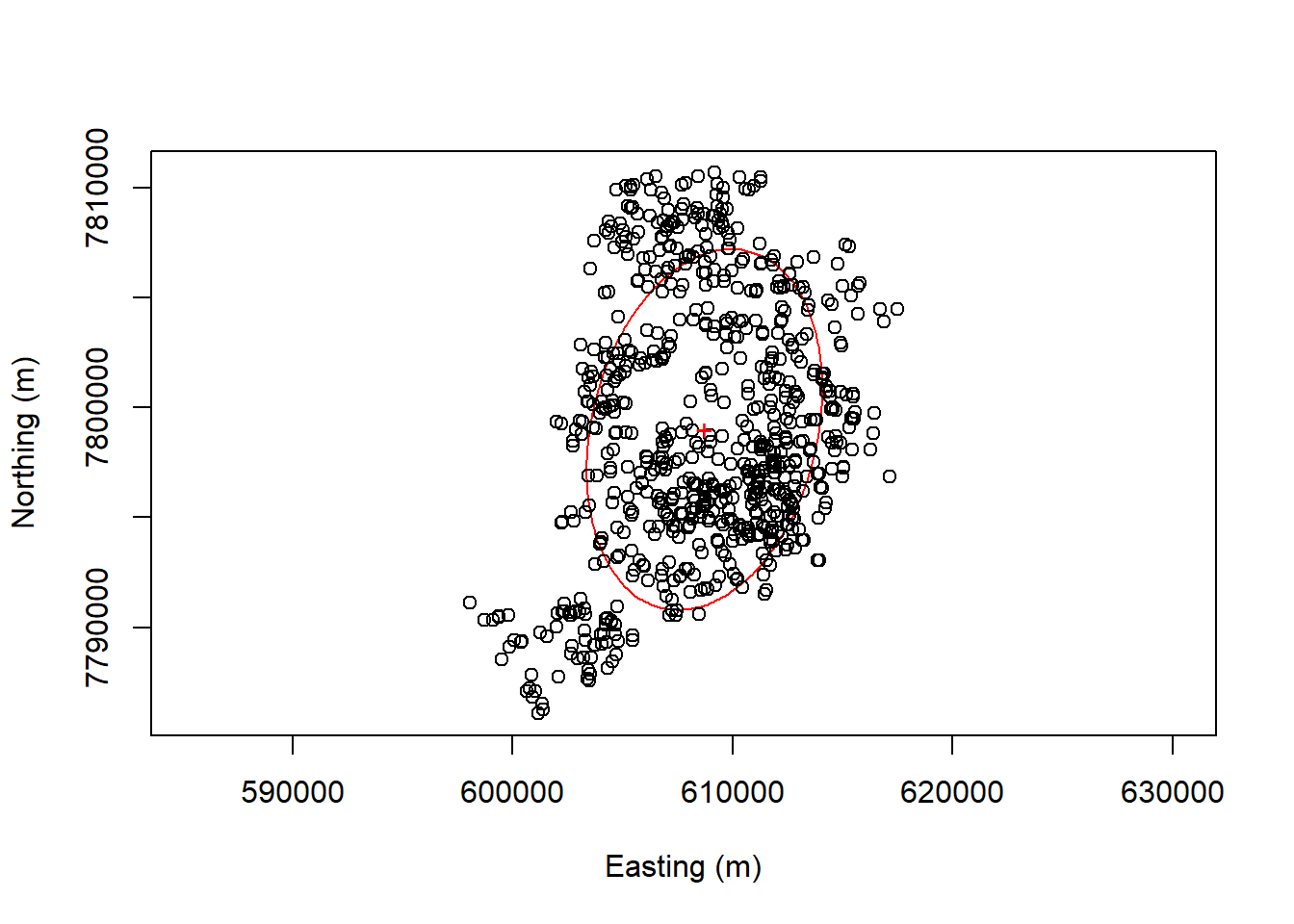
plot_sdd(plotnew=TRUE, plothv=FALSE, plotweightedpts=FALSE, plotpoints=TRUE, plotcentre=TRUE, titletxt="Title", points.col = "gray", xaxis="Easting (m)", yaxis="Southing (m)", centre.col="black", centre.pch = 25)
plot_sde(plotnew=TRUE, plothv=FALSE, plotweightedpts=FALSE, plotpoints=TRUE, plotcentre=TRUE, titletxt="Title", points.col = "gray", xaxis="Easting (m)", yaxis="Southing (m)", centre.col="black", centre.pch = 25)
Centro Médio e Distância Padrão ponderados
wtc <- function(g,w){
if (!(is(g,"sf")) | !(w %in% colnames(g))){
stop(paste("requires an sf object with at a column",w))
}
centers = st_coordinates(st_centroid(st_geometry(g)))
# crsx = st_crs(g) how could i reuse the CRS of g? do i need that?
out = st_point(c(weighted.mean(centers[,"X"],g[[w]]), weighted.mean(centers[,"Y"],g[[w]])))
return(out)
}plot(st_geometry(data))
plot(st_centroid(st_union(data)),col="red",pch=3,add=TRUE, lwd=2)
plot(wtc(data,"NUMERO"),col="blue",pch=3,add=TRUE, lwd=2)
Autocorrelação espacial
A natureza dos dados espaciais
As questões de escala geográfica, agregação e nível de detalhamento são fundamentais para construir representações apropriadas do mundo.
Diferentes medidas obtidas do mundo real covariam, e compreender a natureza espacial da covariação pode nos ajudar a entender melhor os fenômenos.
Na representação do mundo real, é importante incorporar informações sobre como dois ou mais fatores COVARIAM espacialmente.
Análise dos impactos de investimentos no sistema público de transporte: Avaliação de como os preços dos imóveis aumentam à medida que aumenta a proximidade das estações.
Os efeitos de proximidade são fundamentais para representar e compreender a variação espacial e para reunir representações incompletas de lugares únicos.
Não dá para analisar proximidade numa planilha!!!
Primeira Lei da Geografia
“No mundo, todas as coisas se parecem, mas coisas mais próximas são mais parecidas que aquelas mais distantes” 1
Tobler, W. R. 1970. A computer movie simulating urban growth in the Detroit region. Economic Geography 46: 234–40.
Autocorrelação espacial
A relação entre eventos próximos no espaço pode ser formalizada no conceito de AUTOCORRELAÇÃO ESPACIAL
A relação entre eventos consecutivos no tempo pode ser formalizada no conceito de AUTOCORRELAÇÃO TEMPORAL
“No mundo, todas as coisas se parecem, mas coisas mais próximas são mais parecidas que aquelas mais distantes” DEFINIÇÃO SUCINTA DE AUTOCORRELAÇÃO ESPACIAL (positiva)
Heterogeneidade Espacial
- Refere-se à variação no relacionamento entre as variáveis no espaço
- Tendência de lugares de serem diferentes uns dos outros.
- Heterogeneidade maior com o aumento da distância
- Alguns fenômenos geográficos variam de maneira gradual através do espaço (estacionariedade), enquanto outros podem apresentar extrema irregularidade, violando a Lei de Tobler
- Diz respeito a aspectos da estrutura socioeconômica no espaço
Medidas de autocorrelação espacial
As medidas de autocorrelação espacial procuram lidar simultaneamente com similaridades na localização dos objetos espaciais e de seus atributos
- Autocorrelação Positiva (Lei de Tobler): Feições similares em localização também são similares em atributos
- Autocorrelação Negativa (oposição à Lei de Tobler): Feições similares em localização tendem a ter atributos menos similares do que feições mais distantes
- Ausência de Autocorrelação: Quando atributos são independentes da localização
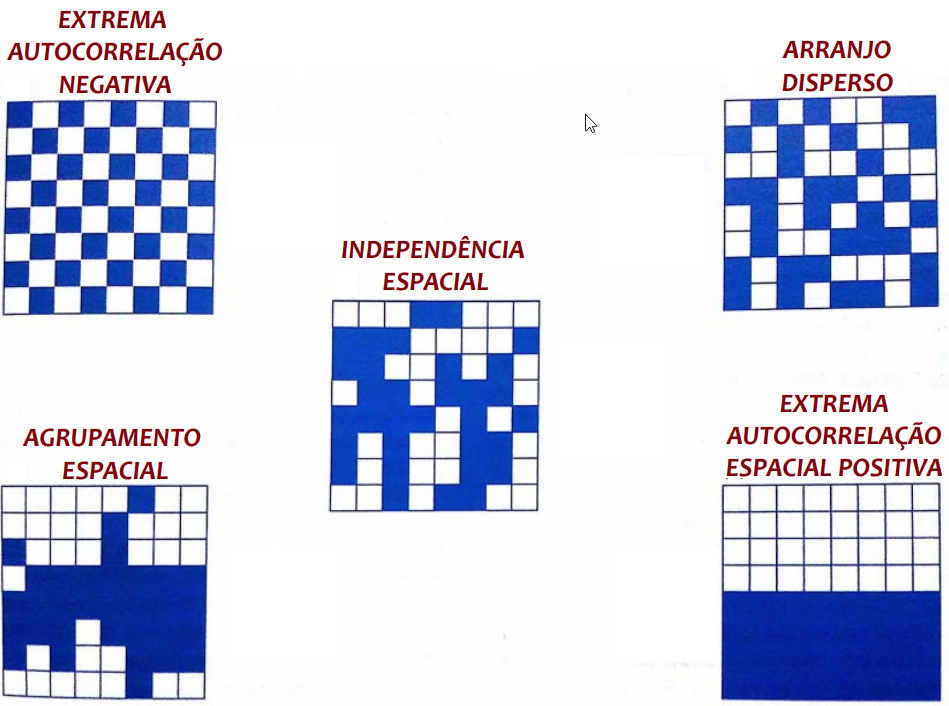
A interrelação das várias propriedades de um local é um aspecto importante da natureza dos dados geográficas e é fundamental para o entendimento sobre o mundo real.
NO ENTANTO, ELA TAMBÉM É UMA PROPRIEDADE QUE DESAFIA A ANÁLISE DA ESTATÍSTICA CONVENCIONAL, POIS A MAIORIA DOS MÉTODOS ASSUME INDEPENDÊNCIA DAS OBSERVAÇÕES (CORRELAÇÃO ESPACIAL = ZERO)
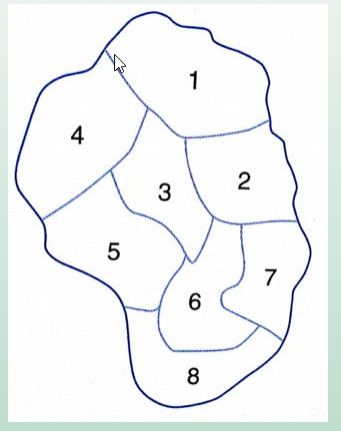
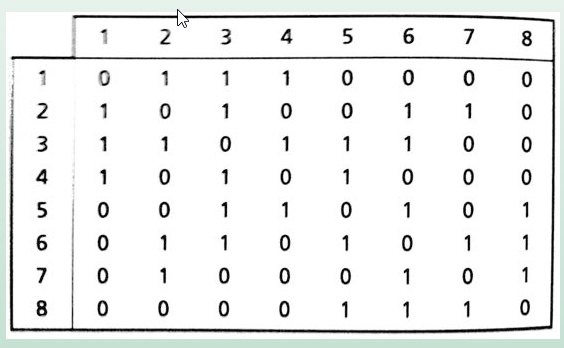
Matriz de vizinhança
Para comparar a similaridade de atributos geográficos em feições vizinhas é importante estabelecer um CRITÉRIO DE VIZINHANÇA.
Baseado neste critério, precisamos definir uma matriz de pesos W na qual cada elemento wij mede a proximidade/vizinhança entre i e j (i identificando a linha; j identificando a coluna da matriz)
Um critério de vizinhança comumente adotado: CONTIGUIDADE
wij = 1, se as regiões i e j são contíguas (ou seja, são vizinhas).
wij = 0, caso contrário.
Matriz de pesos
Critérios de vizinhança
Contiguidade: Rook (torre) e Queen (rainha)
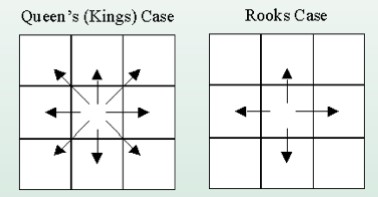
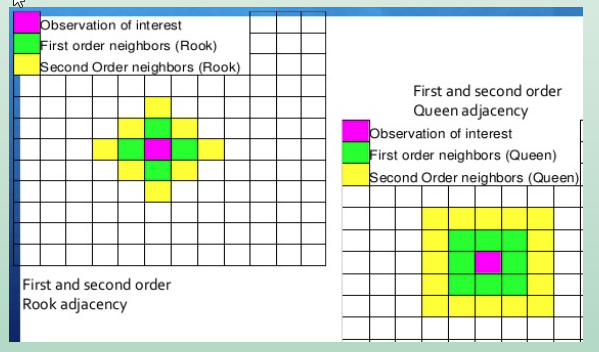
Ordem de contiguidade
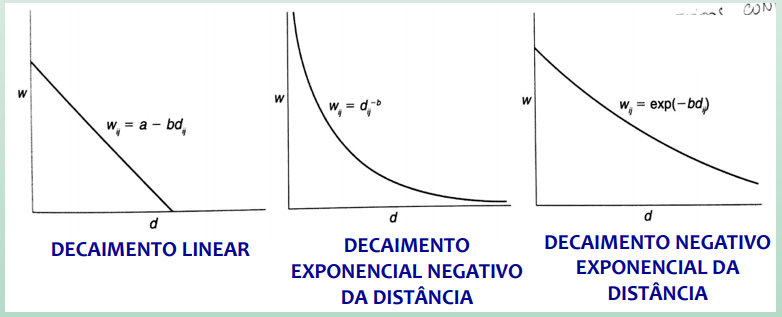
DISTÂNCIA: - “n” vizinhos mais próximos; - distância máxima; - funções de distância (wij com valores contínuos)
O critério adotado para construir uma matriz de vizinhança revela a estrutura espacial considerada na análise, e pode alterar os resultados das medidas de autocorrelação espacial.
Portanto, vale a pena testar alguns critérios alternativos para a definição de “vizinhança” (contiguidade, distância…) e, consequentemente, para a definição da matriz de vizinhança - também conhecida como matriz de pesos ou matriz de proximidade espacial.
Índices de autocorrelação espacial
Índices Globais de Associação Espacial
- Apresenta uma medida única para toda a área analisada.
- Índice de Moran (I)
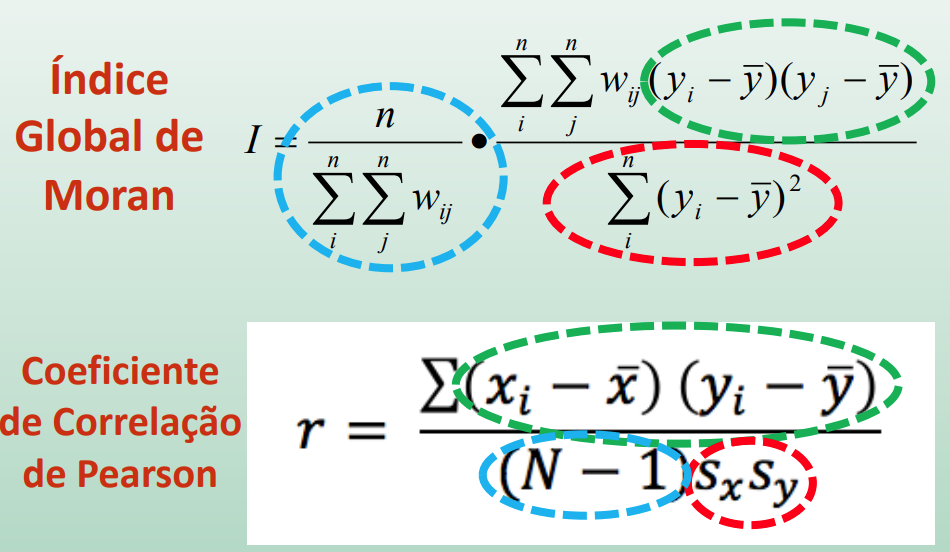
Índice global de Moran
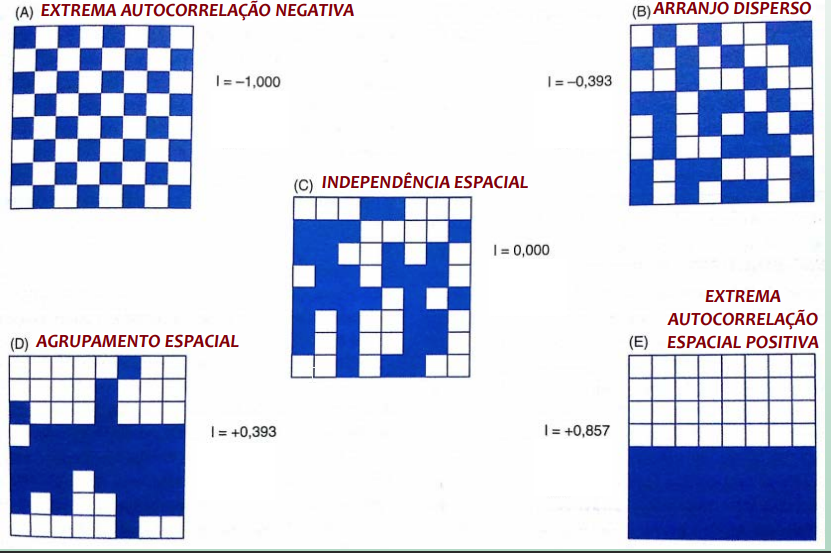
É um índice global de autocorrelação espacial, que varia entre -1 e 1
I = 1
Extrema Autocorrelação Positiva (Lei de Tobler): Feições similares em localização também são similares
em atributos
I = -1
Extrema Autocorrelação Negativa (oposição à Lei de Tobler): Feições similares em localização tendem a ter atributos menos similares do que feições mais distantes
I = 0
Ausência de Autocorrelação: Quando atributos são independentes da localização
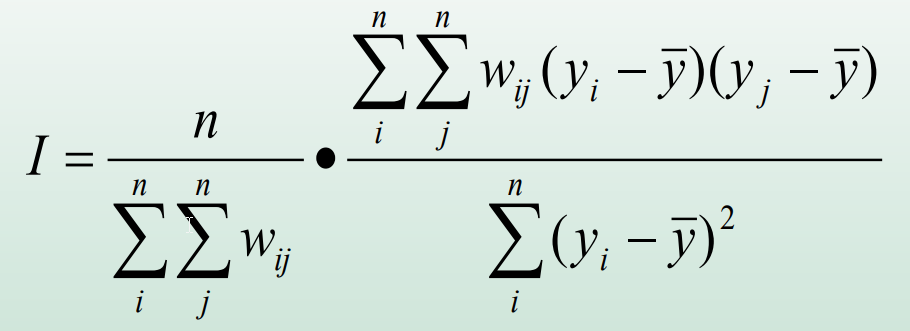
wij é o peso, wij=1 se observações i e j são vizinhas.
yi and ybarra representam o valor da variável na localização i e a média da variável, respectivamente.
n é o número total de observações
Estruturado de maneira semelhante ao coeficiente de correlação de Pearson: uma medida padronizada de covariância
De forma geral, o Índice de Moran presta-se a um teste cuja hipótese nula é de independência espacial. Neste caso, seu valor seria ZERO.
Valores positivos (entre 0 e +1) indicam autocorrelação positiva Valores negativos (entre 0 e -1) indicam autocorrelação negativa.
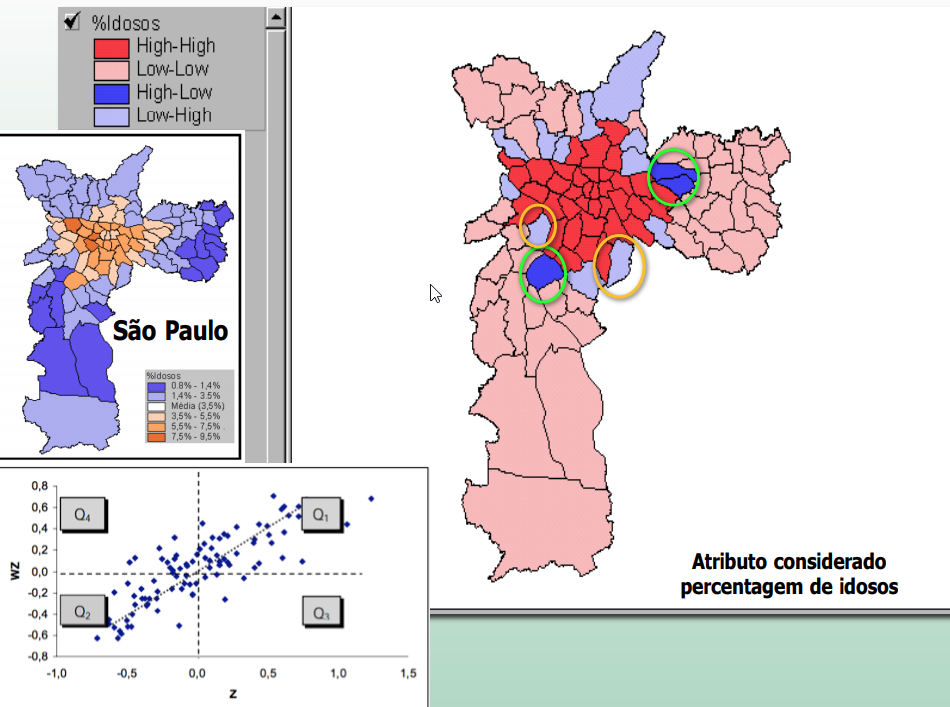
No exemplo da variável “consumo de água”, obtemos um I = 0,59 (vizinhança por contiguidade – queen). Será que este valor representa uma correlação espacial significativa estatisticamente????
Teste de Pseudo Significância
Para estimar a significância do índice, seria preciso associar a este uma distribuição estatística, sendo mais usual relacionar a estatística teste à distribuição normal.
Porém, para evitar pressupostos em relação à distribuição, a abordagem mais comum é um TESTE DE PSEUDO-SIGNIFICÂNCIA.
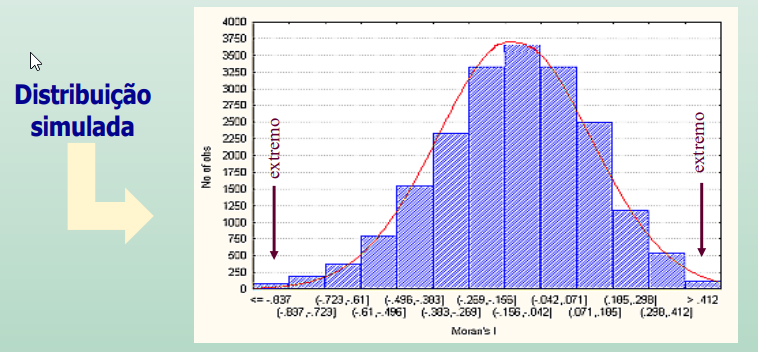
No TESTE DE PSEUDO-SIGNIFICÂNCIA são geradas diferentes permutações dos valores de atributos associados às regiões.
Cada permutação produz um novo arranjo espacial, onde os valores estão redistribuídos entre as áreas. Como apenas um dos arranjos corresponde à situação observada, pode-se construir uma distribuição empírica de I.
No nosso exemplo, seria como se fizéssemos inúmeras permutações com os valores de consumo de água, atribuindo-os aleatoriamente para os diversos municípios e calculando o Índice de Moran para cada uma destas permutações aleatórias.
Faríamos isso, por exemplo 999 vezes! E obteríamos, portanto, 999 valores para o Índice de Moran + o valor do índice de Moran construído sobre os dados observados. Com estes 1000 valores de I, poderíamos contruir uma distribuição do índice.
Se o valor do índice I medido originalmente corresponder a um “extremo” da distribuição simulada, então trata-se de valor com significância estatística.
H0: não há autocorrelação espacial
Diagrama de espelhamento de Moran
- Maneira adicional de visualizar a dependência espacial
- Construído com base nos valores padronizados (escore-z)
- A ideia é comparar os valores padronizados do atributo numa área com a média dos seus vizinhos, construindo um gráfico bidimensional de z (valores padronizados) por wz (média dos vizinhos).
Z-Score / escores-z
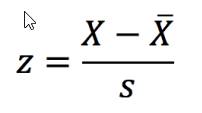
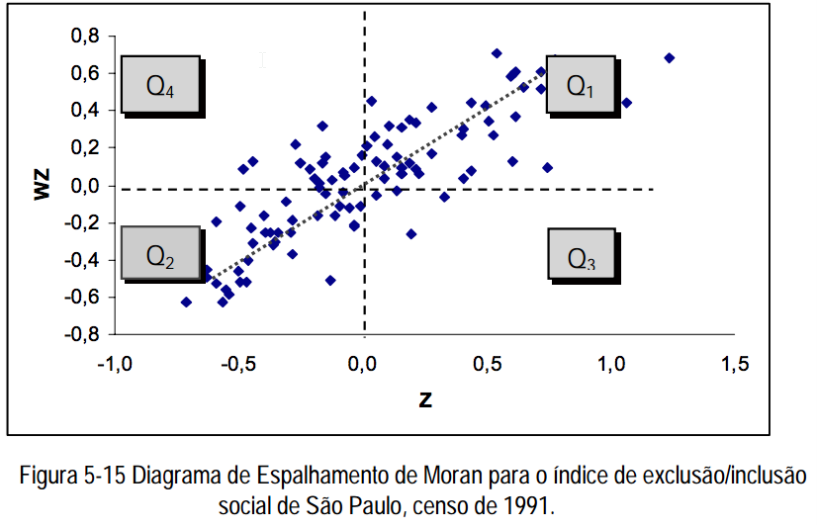
Q1 (valores positivos, médias positivas) e Q2 (valores negativos, médias negativas): indicam pontos de associação espacial positiva, no sentido que uma localização possui vizinhos com valores semelhantes.
Q3 (valores positivos, médias negativas) e Q4 (valores negativos, médias positivas): indicam pontos de associação espacial negativa, no sentido que uma localização possui vizinhos com valores distintos.
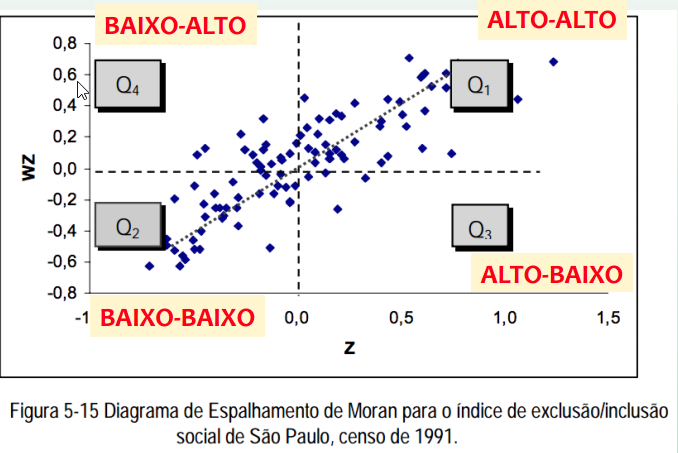
Os pontos em Q3 e Q4 podem ser vistos como extremos:
afastados da reta de regressão linear
regiões que não seguem o mesmo processo de dependência espacial das demais observações.
Marcam regiões de transição entre regimes espaciais distintos.
O Diagrama também pode ser apresentado na forma de mapa temático, no qual cada polígono é apresentado indicando-se seu quadrante no diagrama de espalhamento