Gráficos no R
Ferramentas básicas de construção de gráficos no R
x1 <- rnorm(100)
y1 <- rnorm(100)
plot(x1,y1)
plot(x1,y1,pch=16, col='red')
x2 <- seq(0,2*pi,len=100)
y2 <- sin(x2)
plot(x2,y2,type='l')
plot(x2,y2,type='l', lwd=3, col='darkgreen') 
plot(x2,y2,type='l', col='darkgreen', lwd=3, ylim=c(-1.2,1.2));
y2r <- y2 + rnorm(100,0,0.1)
points(x2,y2r, pch=16, col='darkred')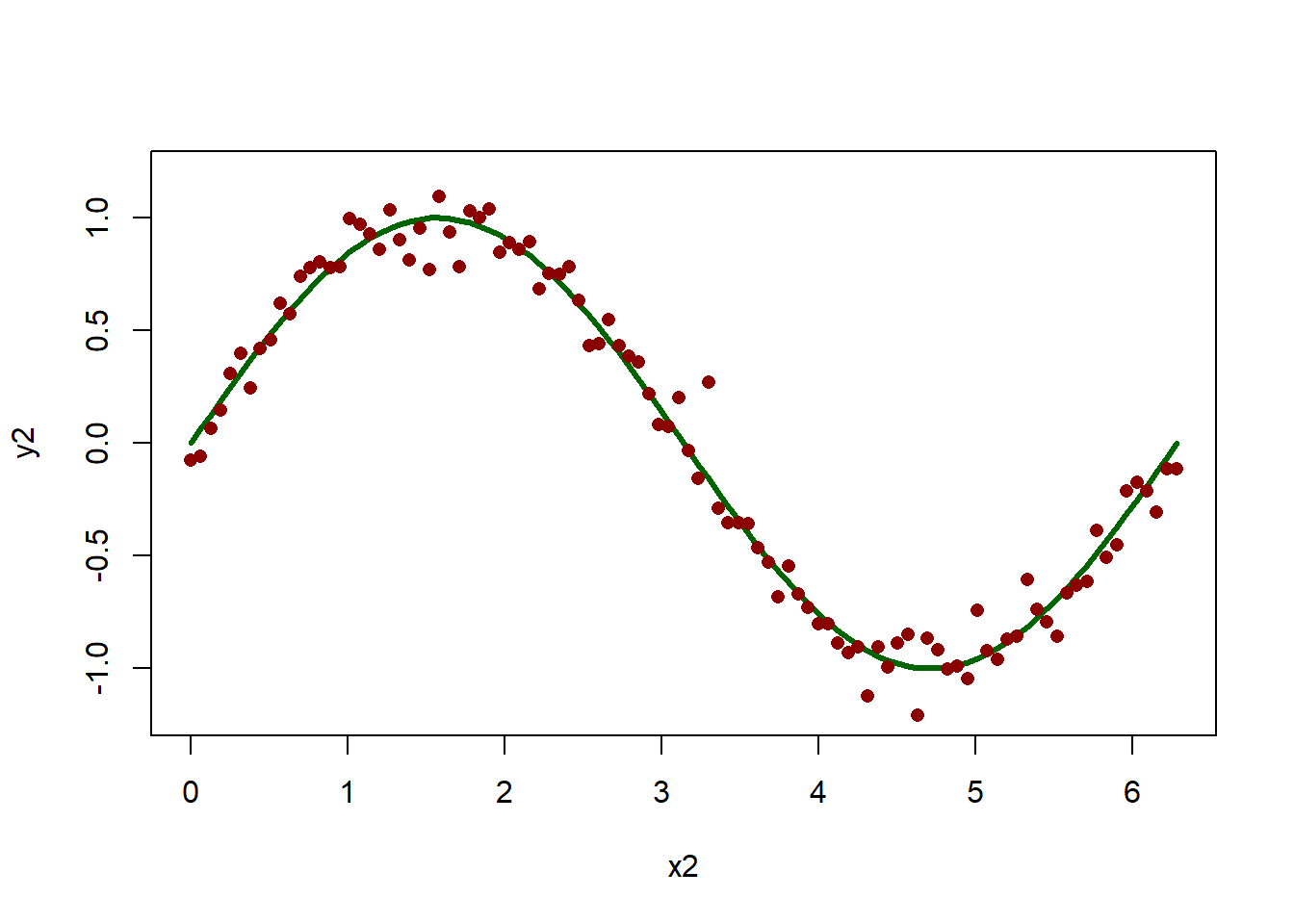
Carregando mapas no R
#install.packages("GISTools", depend = T)
library(GISTools)
# library(GISTools)
data(georgia)
# seleciona o primeiro elemento - Município Appling
appling <- georgia.polys[[1]]
# determinar a extensão da representação
plot(appling, asp=1, type='n', xlab="Easting", ylab="Northing")
# plot the selected features with hatching
polygon(appling, density=14, angle=135) 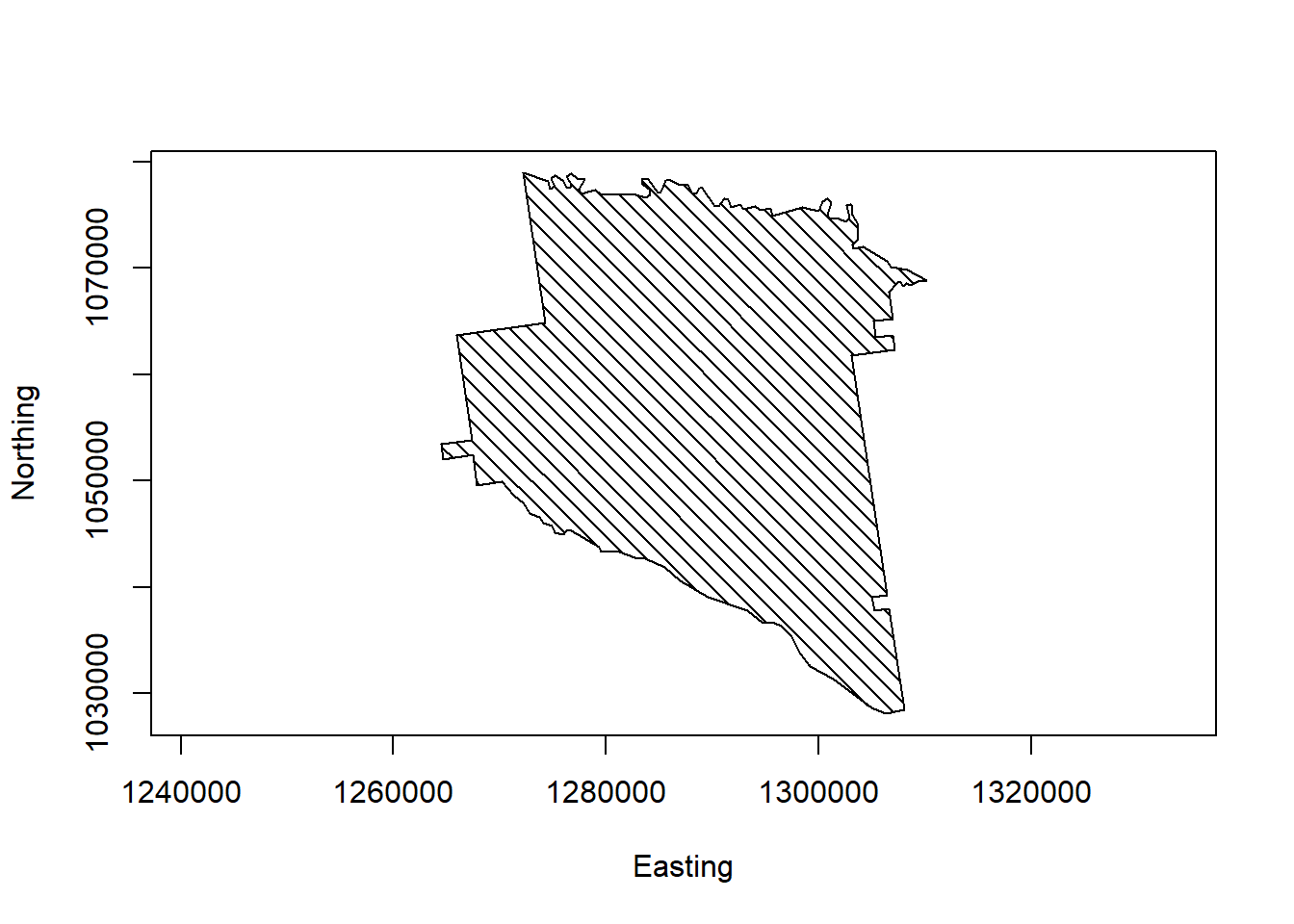
Introdução à gramática de gráficos com ggplot2
Para este tutorial vamos usar novamente dados de Fakeland, como fizemos no tutorial 5. Em vez de apenas 30 observações, agora trabalharemos com um conjunto maior de cidadãos (200) e menos variáveis, para facilitar nosso trabalho.
Antes de abrir os dados, vamos começar carregando as duas bibliotecas que utilizaremos no tutorial: readr, para ler os dados; e ggplot2, para a produção de gráficos. Você pode simplesmente carregar o pacte tidyverse se preferir.
library(readr)
library(ggplot2)library(tidyverse)## -- Attaching packages --------------------------------------- tidyverse 1.3.1 --## v tibble 3.1.4 v dplyr 1.0.7
## v tidyr 1.1.3 v stringr 1.4.0
## v purrr 0.3.4 v forcats 0.5.1## -- Conflicts ------------------------------------------ tidyverse_conflicts() --
## x dplyr::filter() masks stats::filter()
## x dplyr::lag() masks stats::lag()
## x dplyr::select() masks MASS::select()A seguir, carregue os dados, que estão no repositório da oficina:
url_fake_data <- "https://raw.githubusercontent.com/leobarone/cebrap_lab_programacao_r/master/data/fake_data_2.csv"
fake <- read_delim(url_fake_data, delim = ";", col_names = T)## Rows: 200 Columns: 7## -- Column specification --------------------------------------------------------
## Delimiter: ";"
## chr (4): sexo, educ, partido, candidato
## dbl (3): idade, renda, filhos##
## i Use `spec()` to retrieve the full column specification for this data.
## i Specify the column types or set `show_col_types = FALSE` to quiet this message.ggplot2: uma gramática de dados
Em conjunto com a gramática de manipulação de dados do dplyr, a gramática de gráficos ggplot2 é um dos destaques da linguagem R. Além de flexível e aplicável a diversas classes de objetos (data frames, objetos de mapa e redes, por exemplo), a qualidade dos gráficos é excepcionalmente boa.
Não é, no entanto, tão intuitiva e simples como a gramática de manipulação de dados. Assim, neste breve tutorial vamos priorizar a compreensão da estrutura do código para produzir gráficos com ggplot2 a partir de alguns exemplos simples e propositalmente não cobriremos todas as (inúmeras) possibilidades de visualização.
Você verá, depois de um punhado de gráficos, que a estrutura pouco muda de um tipo de gráfico a outro. Quando precisar de um “tipo” novo de gráfico, ou, como denominaremos a partir de agora, de uma nova “geometria”, bastará aprender mais uma linha de código a ser adicionada ao final de um código já conhecido.
Vamos logo a um primeiro exemplo para clarificar o assunto.
Um primeiro exemplo
Queremos conhecer a distribuição de preferências de candidato à presidência na amostra de cidadãos de Fakeland. Veja como apresentar essa informação com o pacote ggplot2:
ggplot(data = fake, aes(x = candidato)) +
geom_bar()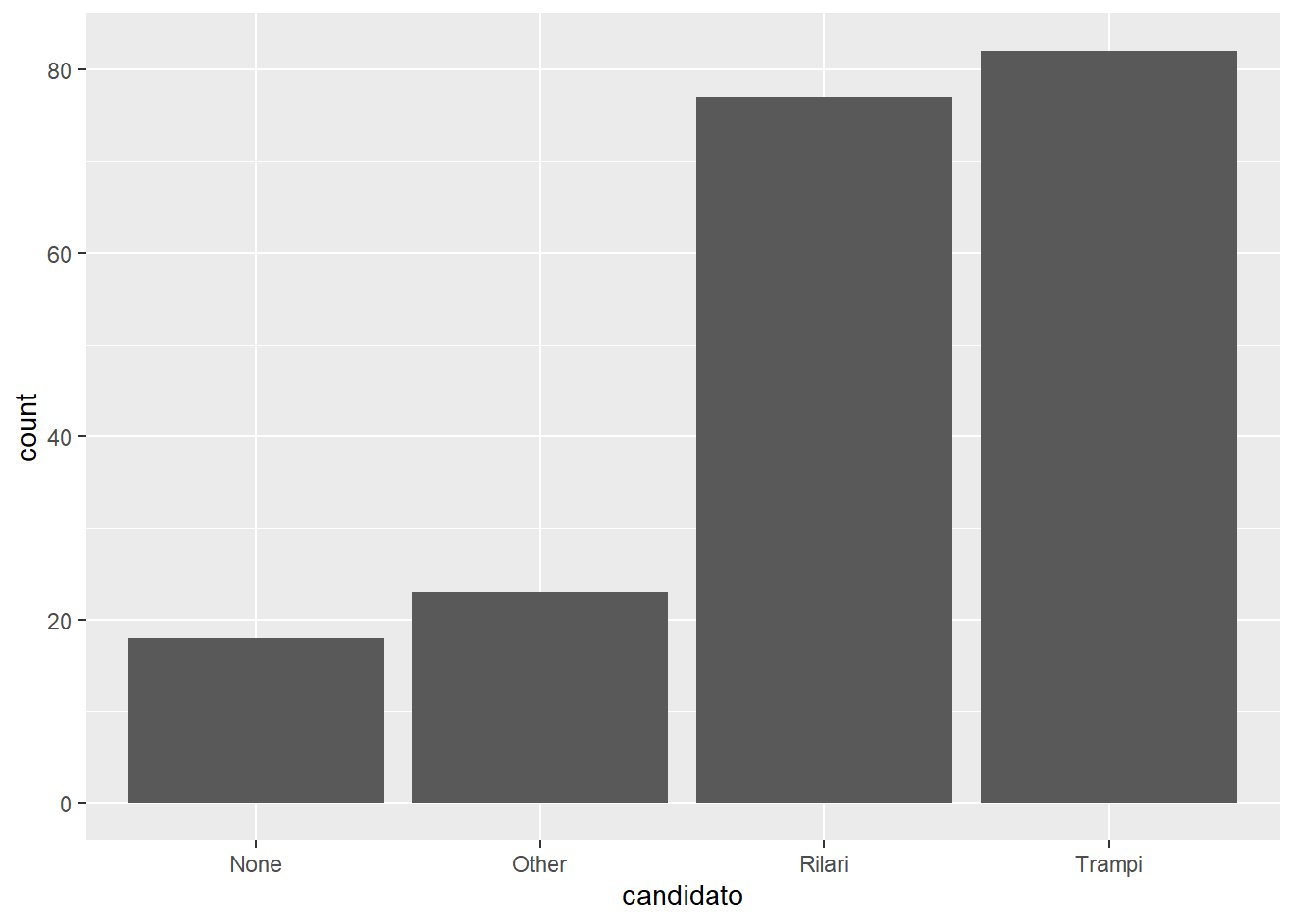
Bastante estranho, não? Vamos olhar cada uma de suas partes.
Comecemos pela primeira linha. A principal função do código é, como era de se esperar, ggplot (sem o 2 mesmo). Note que não estamos fazendo uma atribuição, por enquanto, pois queremos apenas “imprimir” o gráfico, e não guardá-lo como objeto (algo perfeitamente possível!).
O primeiro argumento da função ggplot é “data”, ou seja, o objeto que contém os dados a serem visualizados. No nosso caso, o data frame fake. Diremos que um código de gráfico se compõem de várias camadas, e a primeira delas corresponde aos dados.
Até aqui, nada de novo. A estranhesa vem com as 3 letrinhas “aes” que são a abreviação de “aesthetics”. Está é a segunda “camada”. Aqui definiremos quais variáveis farão parte do gráfico. Estamos trabalhando por enquanto com apenas uma variável, representada no eixo horizontal, ou eixo “x”. Por esta razão preenchemos o parâmetro “x” da “aesthetics” e nada mais.
Mesmo após usar a função ggplot, informar a fonte dos dados e a “aesthetics”, não dissemos nada sobre a geometria do gráfico. A geometria será nossa terceira camada. Como estamos lidando com uma variável nominal (discreta), e queremos observar sua distribuição de probabilidade, podemos usar uma gráfico de barras simples.
Para adicionar uma geometria, colocamos um símbolo de “+” após fechar o parêntesis da função ggplot e, na mesma linha, ou, convencionalmente, na linha seguinte, utilizarmos a função da geometria correspondente. Vamos repetir o gráfico para examinar o código novamente, agora prestando atenção às suas partes:
ggplot(data = fake, aes(x = candidato)) +
geom_bar()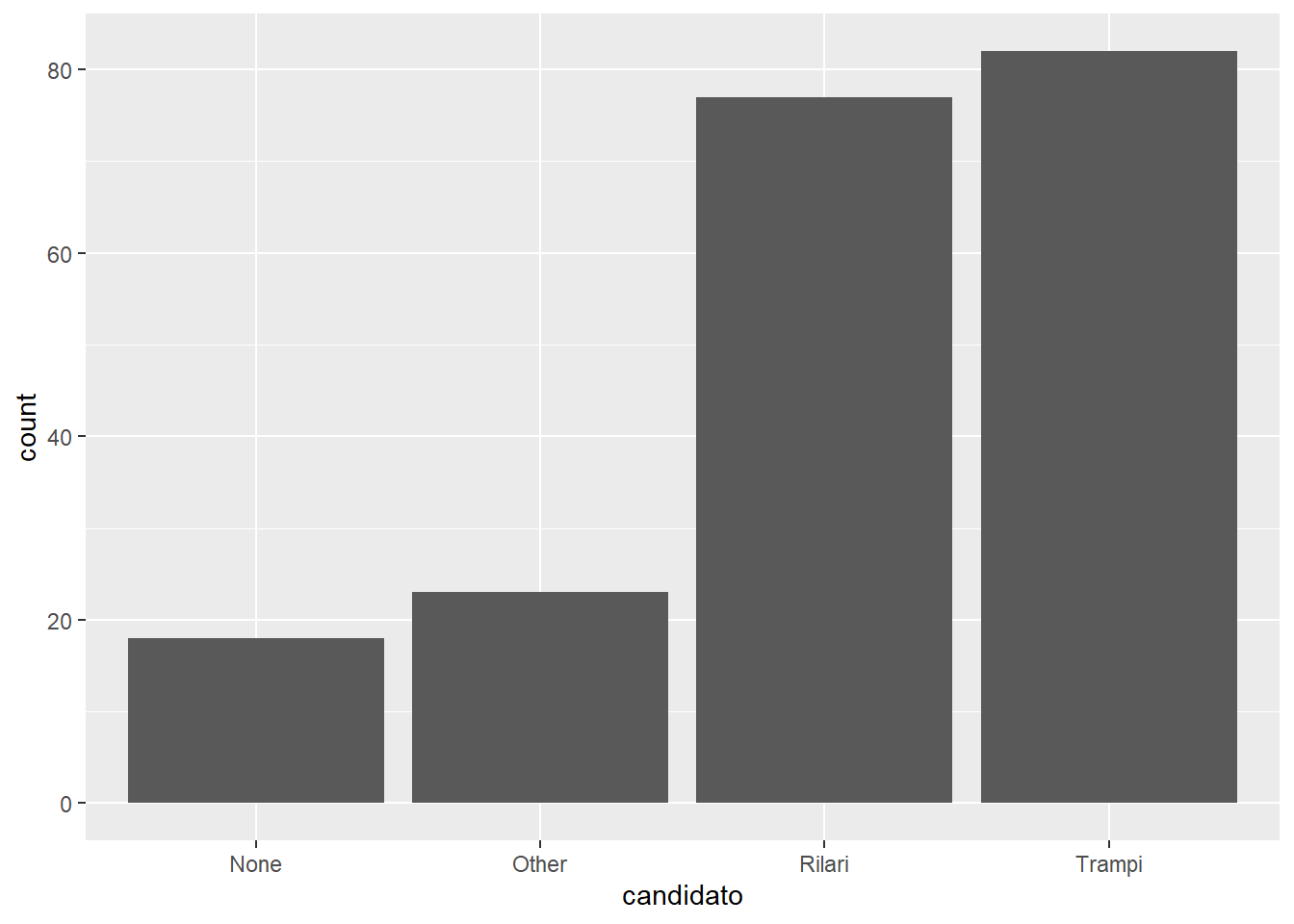
Vamos trocar rapidamente para uma variável contínua, idade, (alterando o valor de “x” dentro de “aesthetics”) e a geometria para histograma (adequado para representar variávels numéricas):
ggplot(data = fake, aes(x = idade)) +
geom_histogram()## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.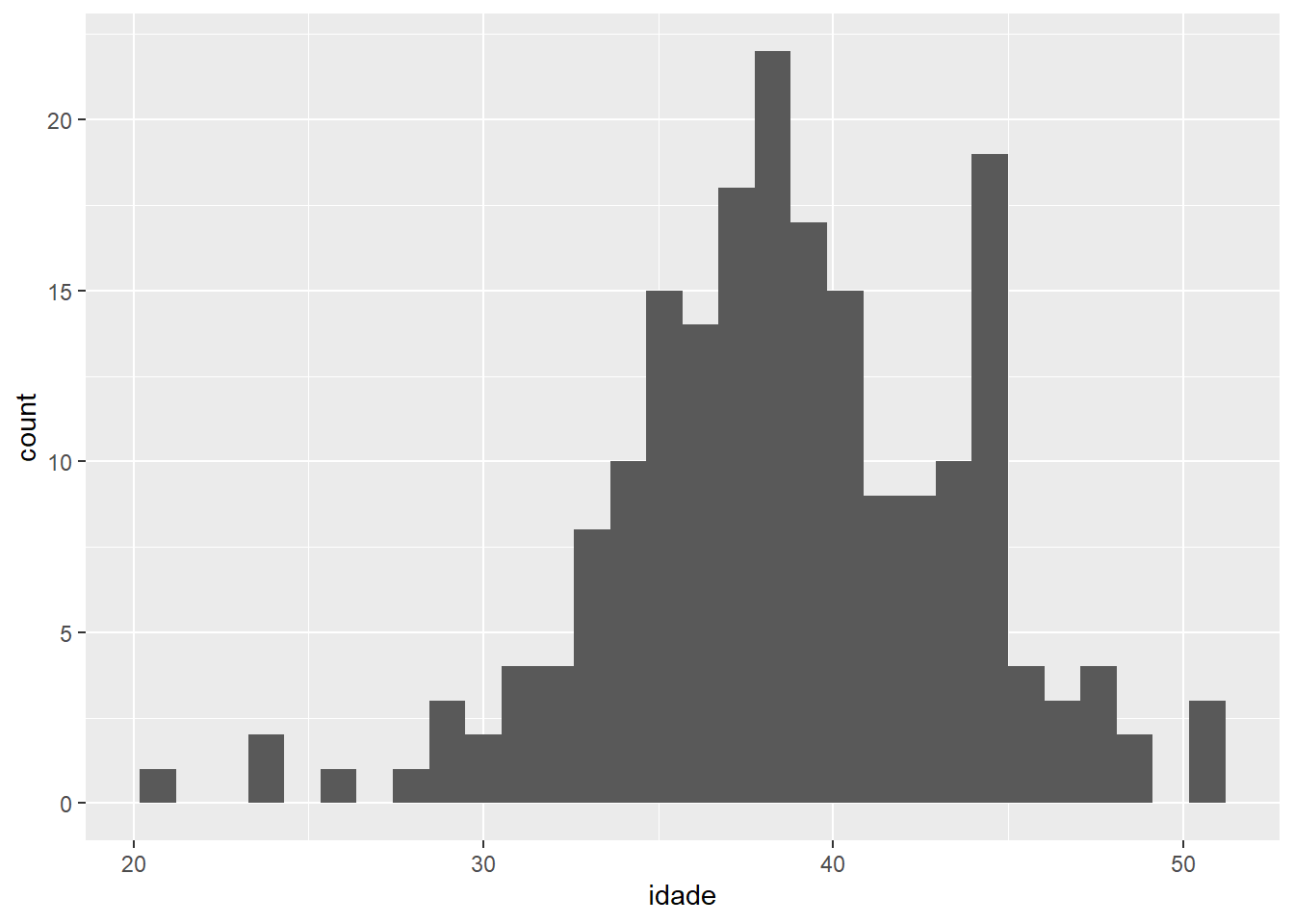
Não avance. Compare os dois códigos com calma e compreenda as diferenças. Note que o tipo de variável que demanda uma(s) geometria(s) específica(s), e não contrário. Pergunte, caso tenha dúvidas.
Variações de histograma e gráfico de densidade
As geometrias, cada uma com sua função, também têm parâmetros que podem ser alterados. Por exemplo, as barras do histograma que acabamos de produzir são muito “fininhas”. Vamos aumentar sua largura, ou seja, vamos representar mais valores do eixo “x” em cada barra do histograma:
ggplot(data = fake, aes(x = idade)) +
geom_histogram(binwidth = 2)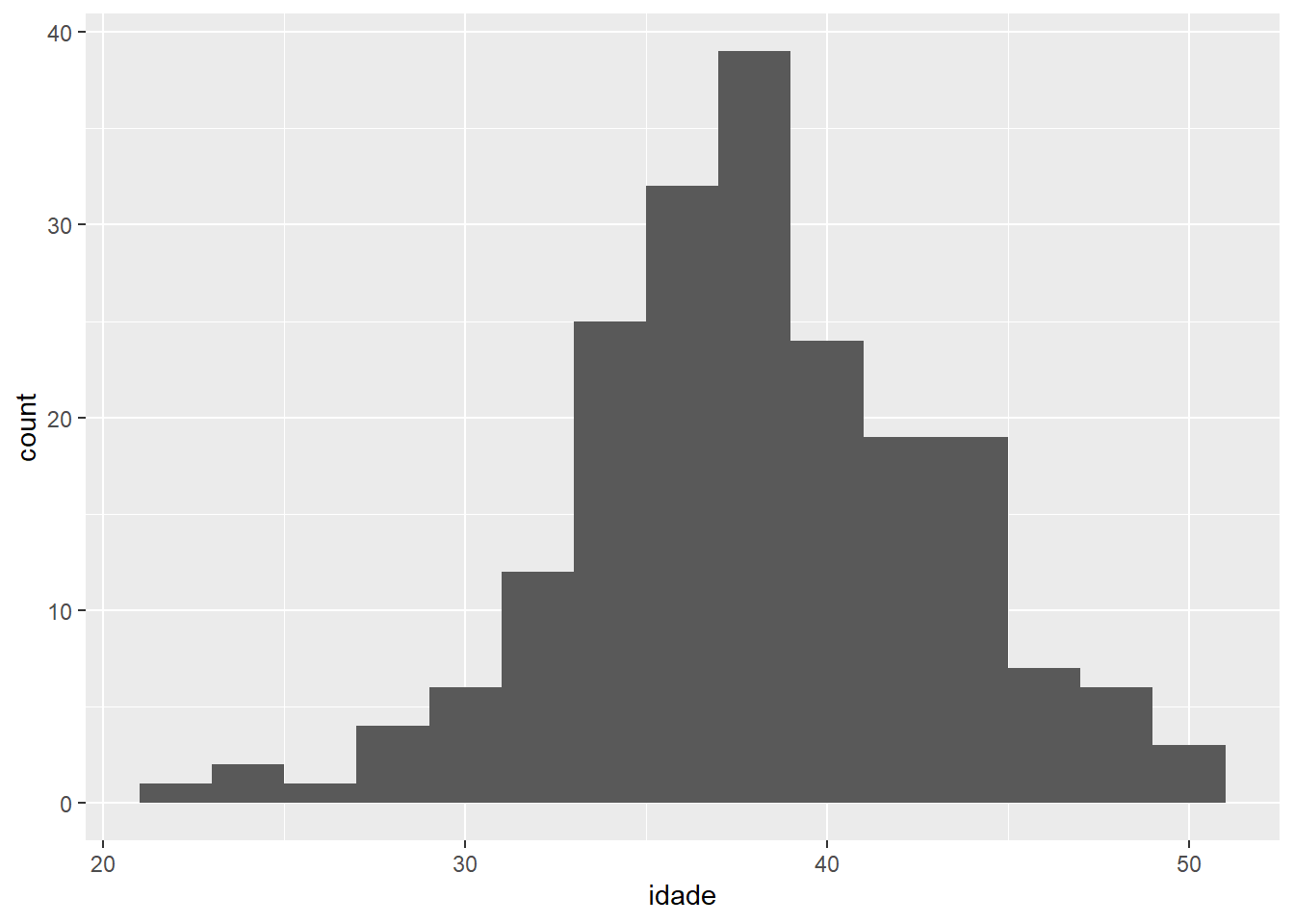
O gráfico está muito cinza. Vamos mudar algumas cores:
ggplot(data = fake, aes(x = idade)) +
geom_histogram(binwidth = 2, colour = "darkred", fill = "green")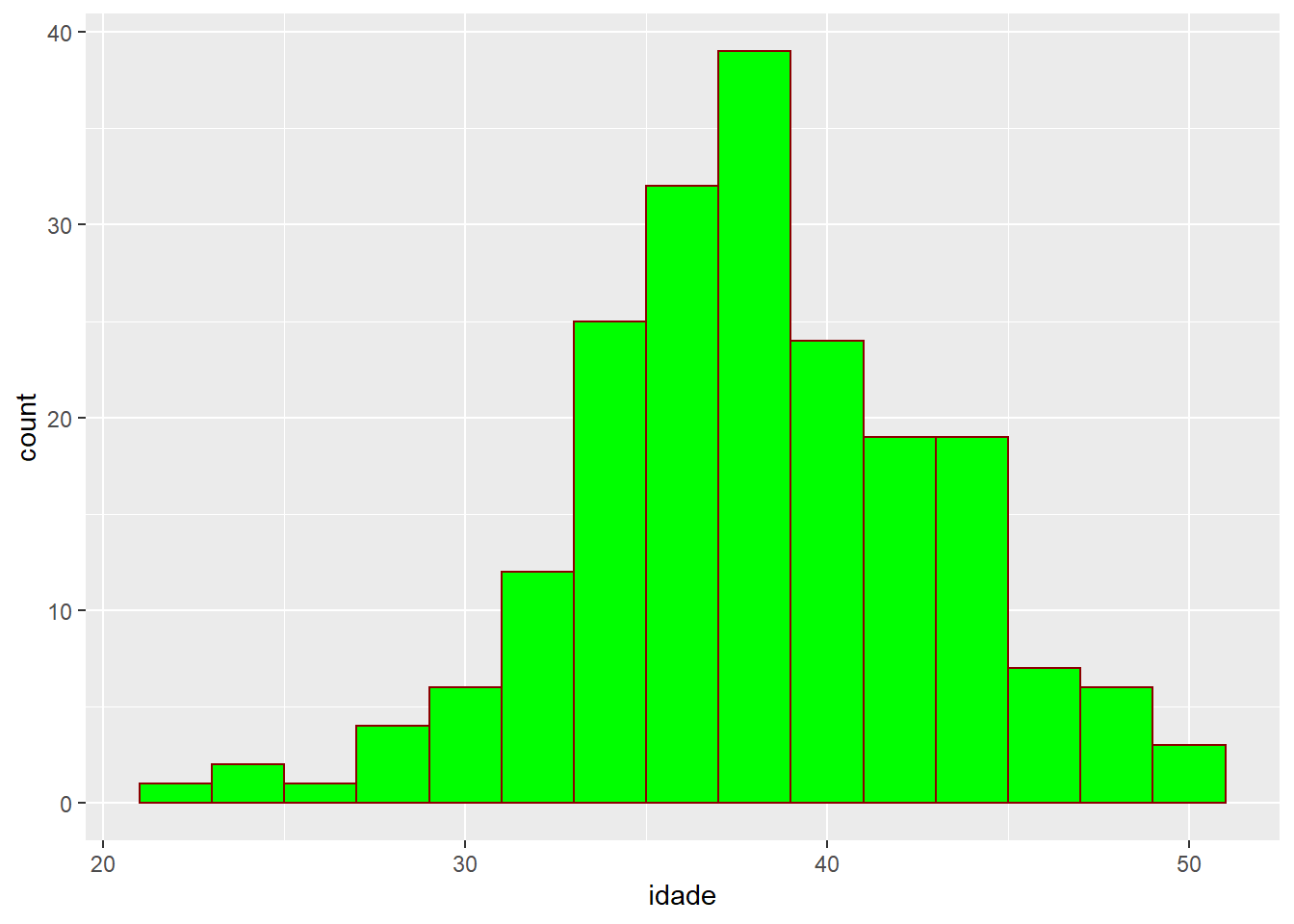
Melhor, não? Certamente não. Mas note que podemo trocar a contornos dos contornos das barras e seu preenchimento. Em geral, os argumentos “colour” e “fill” servem a várias geometrias (e, como veremos abaixo, podemos usá-los também em “aesthetics”).
Curiosidade: R aceita as duas grafias em inglês para a palavra cor, “colour” (britânico) e “color” (americano).
Histogramas são normalmente bastante adequados par variáveis numéricas com valores bastante espaçados, como é o caso de variáveis discretas numéricas (valores inteiros apenas, não podendo assumir valores doidos como pi ou raiz de 2).
Uma alternativa mais elegante ao histograma, e convencionalmente utilizada para variáveis verdadeiramente contínuas, são os gráficos de densidade. Vamos, assim, apenas alterar a geometria para a mesma variável, idade, e observar novamente sua distribuição.
Nota: a partir de agora vamos omitir o nome do parâmetro “data” logo no início do código.
ggplot(fake, aes(x = idade)) +
geom_density()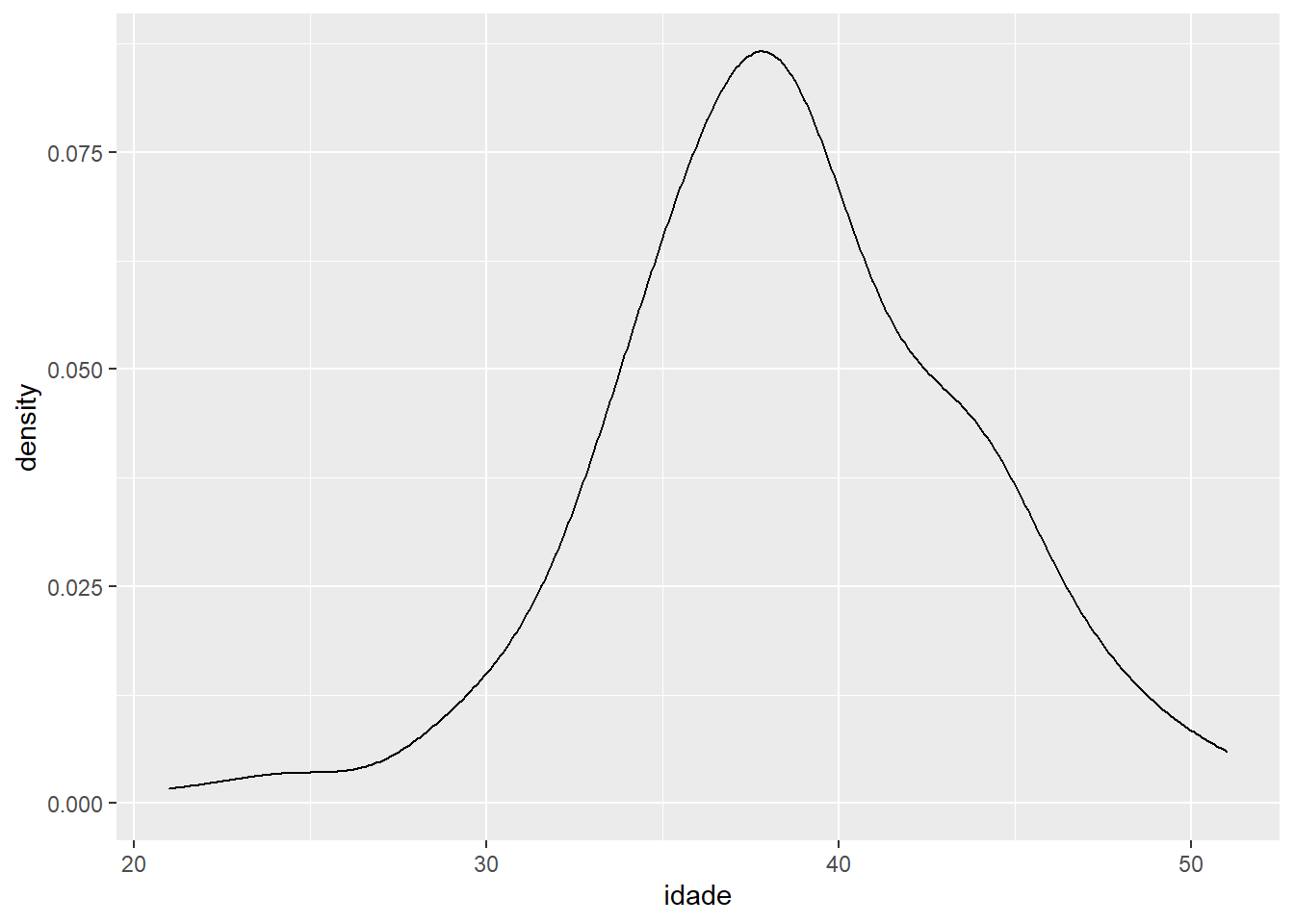
Lindo, mas ainda cinza demais. Vamos adicionar cor à borda:
ggplot(fake, aes(x = idade)) +
geom_density(colour = "blue")
Melhor (melhor?), mas ainda muito branco. Vamos adicionar cor ao interior da curva:
ggplot(fake, aes(x = idade)) +
geom_density(colour = "blue", fill = "blue")
Muito pior. E se deixássemos a curva mais “transparente”?
ggplot(fake, aes(x = idade)) +
geom_density(colour = "blue", fill = "blue", alpha = 0.2)
Agora sim melhorou. Mas nos falta uma referência para facilitar a leitura do gráfico. Por exemplo, seria legal adicionar uma linha vertical que indicasse onde está a média da distribuição. Vamos calcular a média da idade:
media_idade <- mean(fake$idade)Mas estamos tratando de curvas de densidade, não estamos? Nessa geometria não há possibilidade de representar valores com uma linha vertical. Vamos, então, adicionar uma nova geometria, com uma “aesthetics” própria, com novos dados (no caso, um valor único), ao gráfico que já havíamos construído:
ggplot(fake, aes(x = idade)) +
geom_density(colour = "blue", fill = "blue", alpha = 0.2) +
geom_vline(aes(xintercept = media_idade))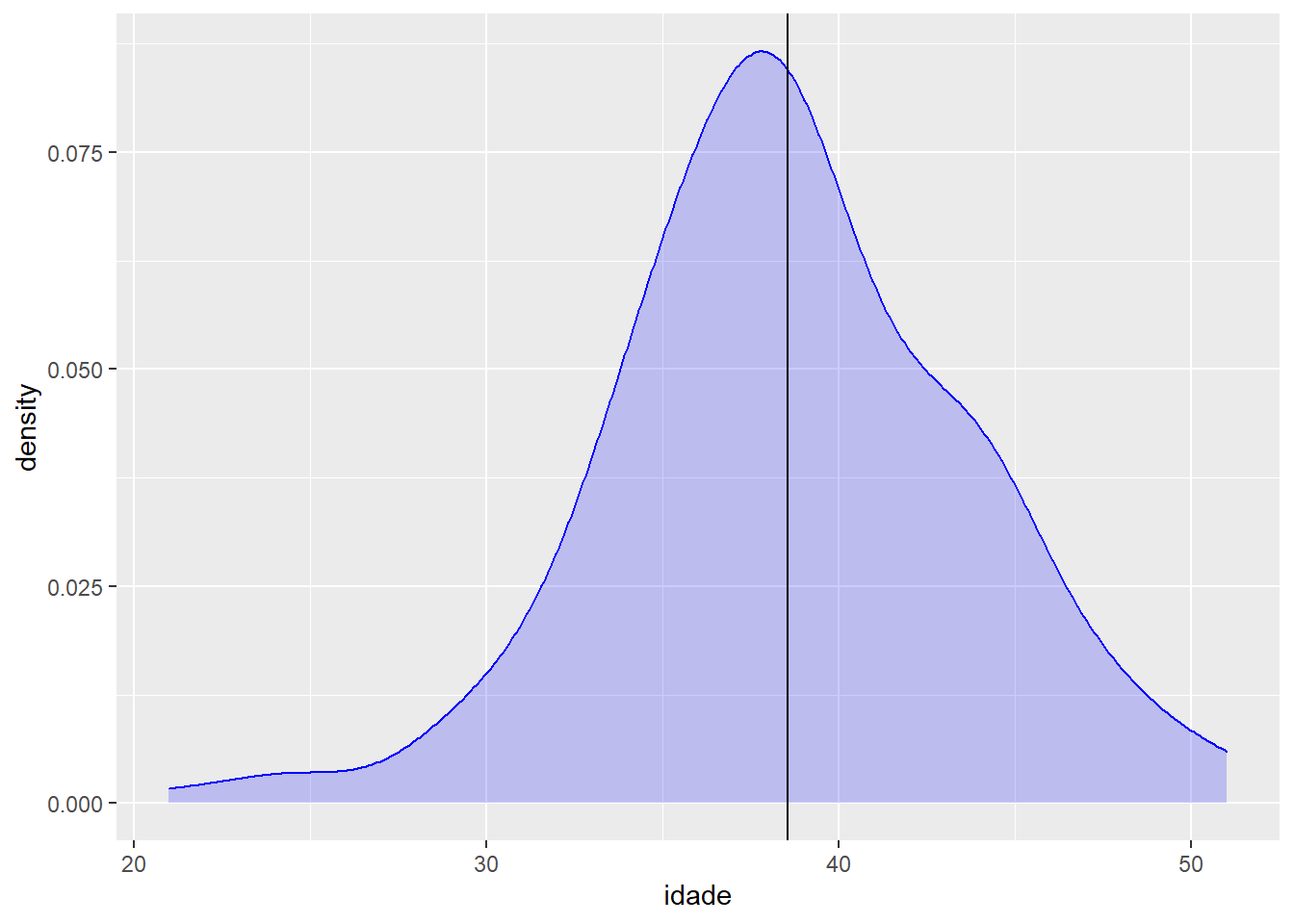
Veja que, com ggplot2 podemos adicionar novas geometrias e dados sempre que precisarmos. É por esta razão que a estrutura do código deste pacote difere tanto da estrutura para gráficos no pacote base. A flexibilidade adicionar geometrias (usando ou não os dados inicialmente apontados) é uma das vantagens do ggplot2
Para tornar o gráfico mais interessante, vamos alterar a forma e a cor da linha adicionada no gráfico anterior:
ggplot(fake, aes(x = idade)) +
geom_density(colour = "blue", fill = "blue", alpha = 0.2) +
geom_vline(aes(xintercept = media_idade),
linetype="dashed",
colour="red")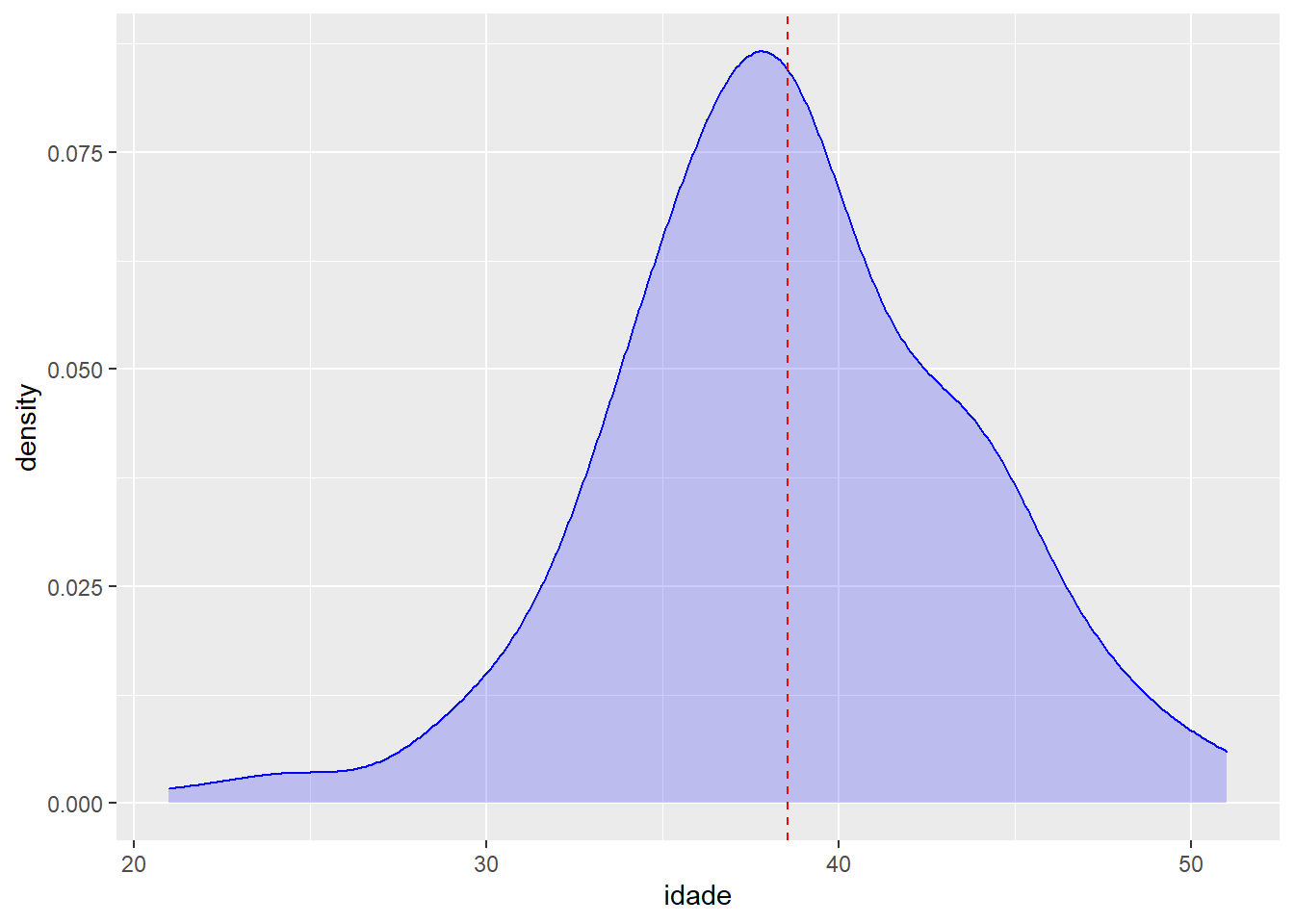
“linetype” é outro parâmetro comum a diversas geometrias (obviamente, as geometrias de linhas).
Vamos dar alguns passos para traz e retornar aos histogramas. E se quisermos comparar as distribuições de idade por sexo, por exemplo? Precisamos filtrar os dados e fazer um gráfico para cada categoria de sexo?
Poderíamos. Mas mais interessante é compara as distribuições em um mesmo gráfico. Como estamos separando uma distribuição de uma variável contínua (idade) em duas, a partir de uma segunda variável (sexo), precisamos adicionar essa nova variável à “aesthetics”. Veja como:
ggplot(fake, aes(x = idade, fill = sexo)) +
geom_histogram(binwidth = 2, position = "identity")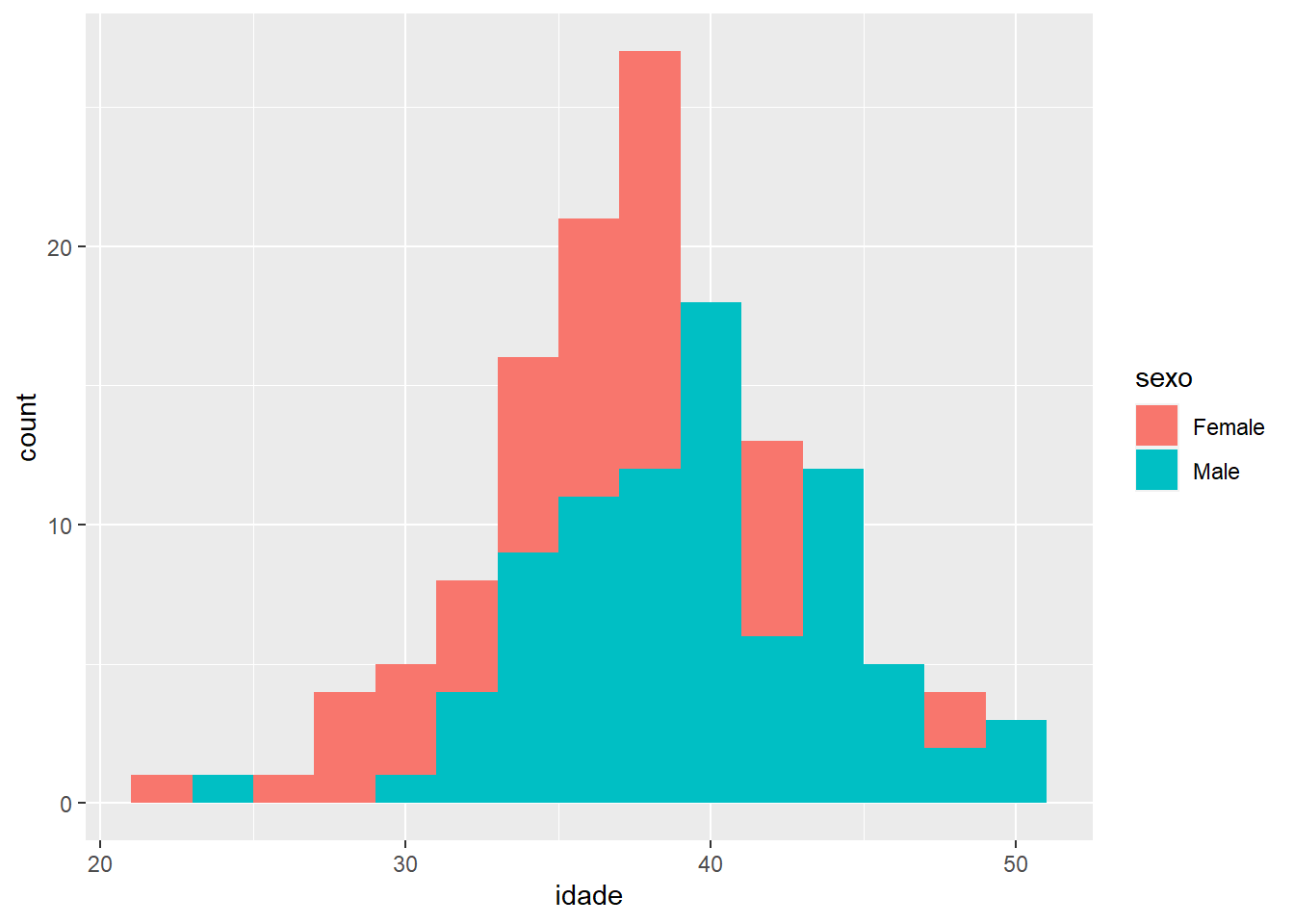
Observe que adicionamos o parâmetro “fill” à “aesthetics”. Isso significa que a variável sexo separará as distribuições de idade em cores de preenchimento diferentes. Conseguem ver as duas distribuições, uma atrás da outra? Note que agora temos uma legenda.
“position” é o que determina como as barras ficarão dispotas uma em relação à outra. Vamos ver outras opções para o mesmo parâmetro (novamente, comum a várias geometrias) para buscar uma opção mais adequada de visualizar os mesmos dados:
ggplot(fake, aes(x=idade, fill = sexo)) +
geom_histogram(binwidth = 2, position = "dodge")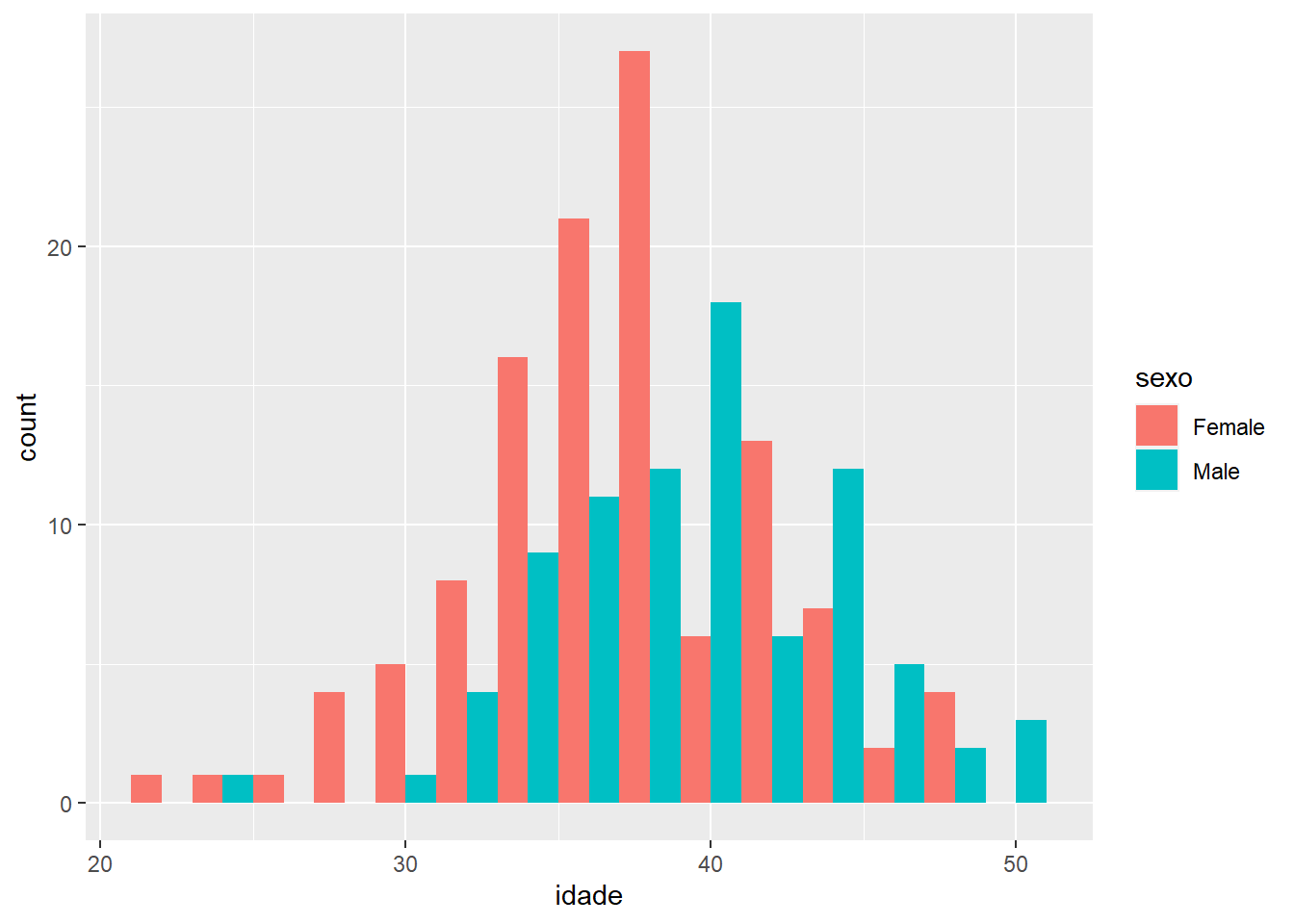
Um pouco melhor?
Vamos tentar algo semelhante com as curvas de densidade. Em vez de “fill”, vamos usar a variável sexo em “colour” na “aesthetics” e separa as distribuições por cores de borda:
ggplot(fake, aes(x = idade, colour = sexo)) +
geom_density()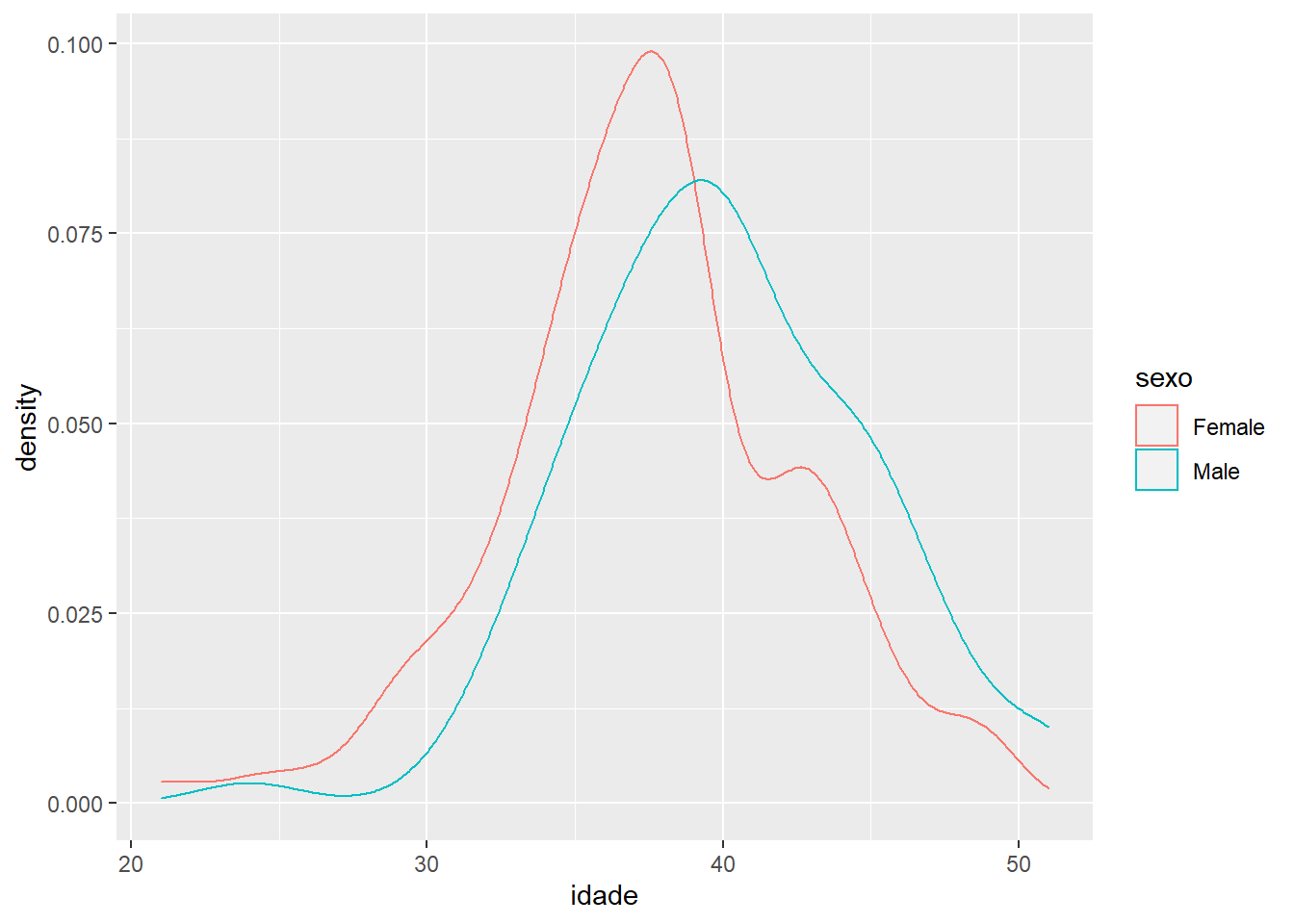
Agora sim está melhor. Vamos adicionar tentar o mesmo com “fill”:
ggplot(fake, aes(x = idade, fill = sexo)) +
geom_density()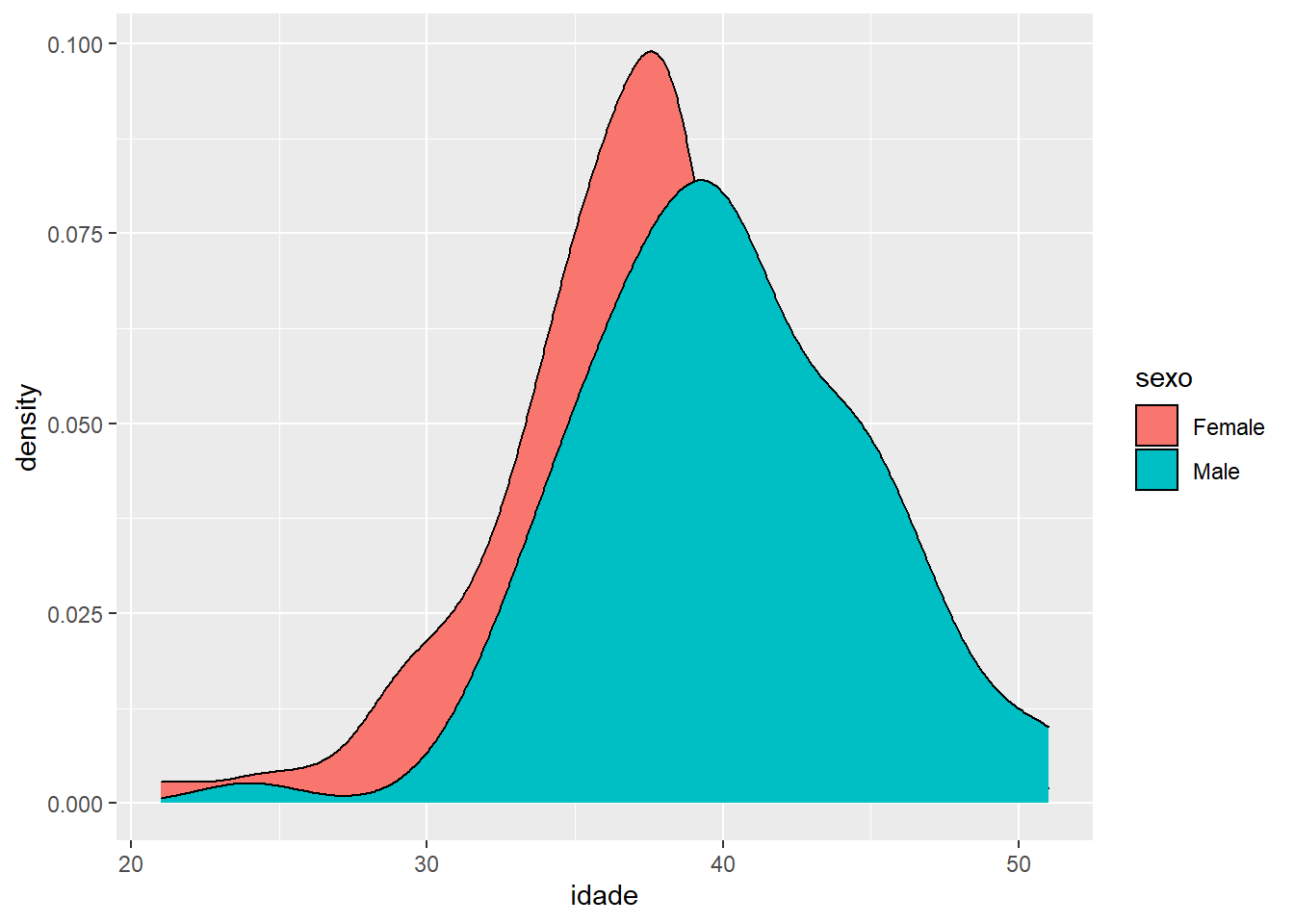
Não ficou muito bom. Mas pode melhorar. Com o parâmetro “alpha”, que já usamos no passado, podemos deixar as distribuições mais “transparentes” e observar as áreas nas quais se sobrepôe:
ggplot(fake, aes(x = idade, fill = sexo)) +
geom_density(alpha = 0.5)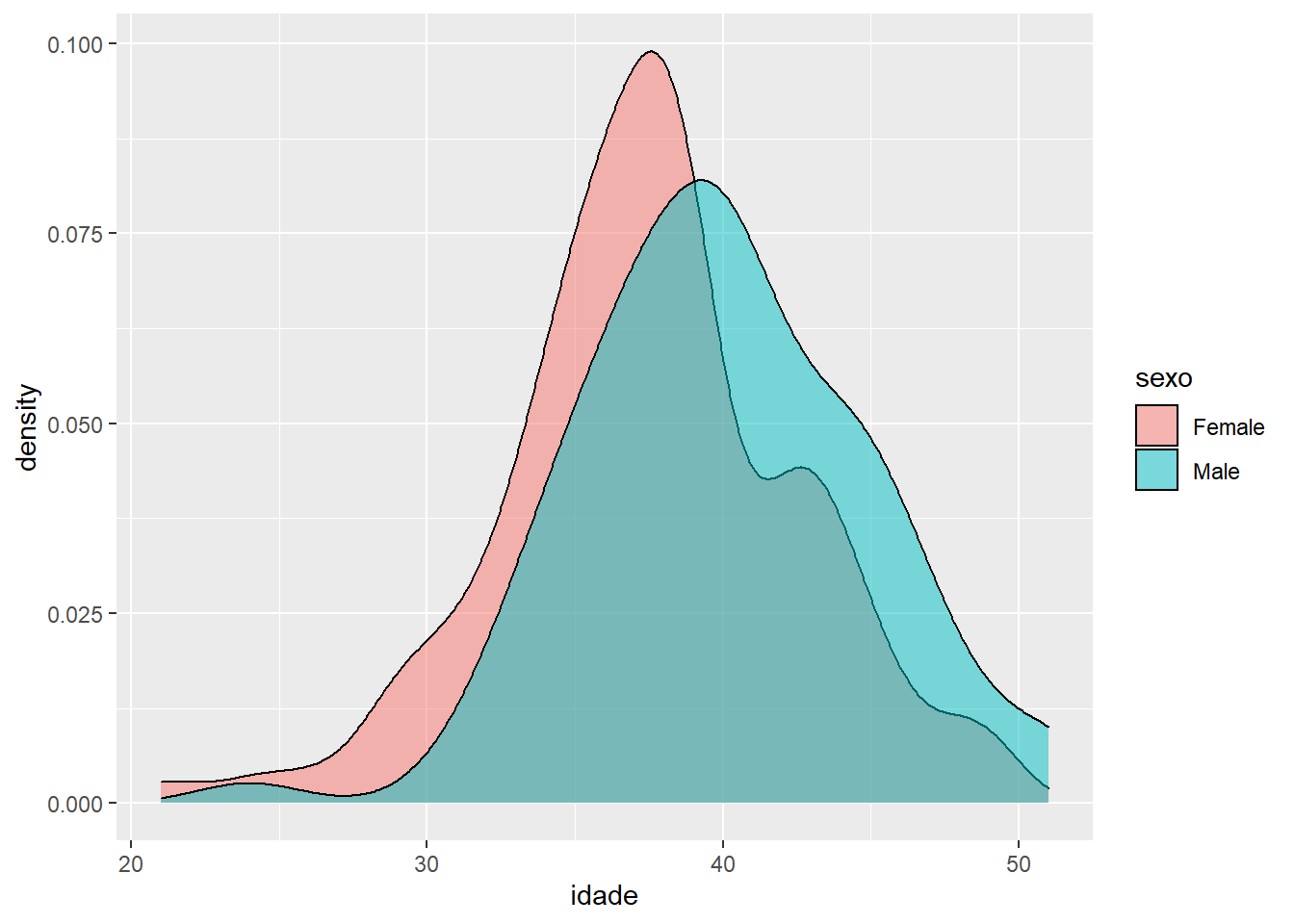
Finalmente, podemos usar “fill” e “colour” juntos na “aesthetics”
ggplot(fake, aes(x = idade, fill = sexo, colour = sexo)) +
geom_density(alpha = 0.5)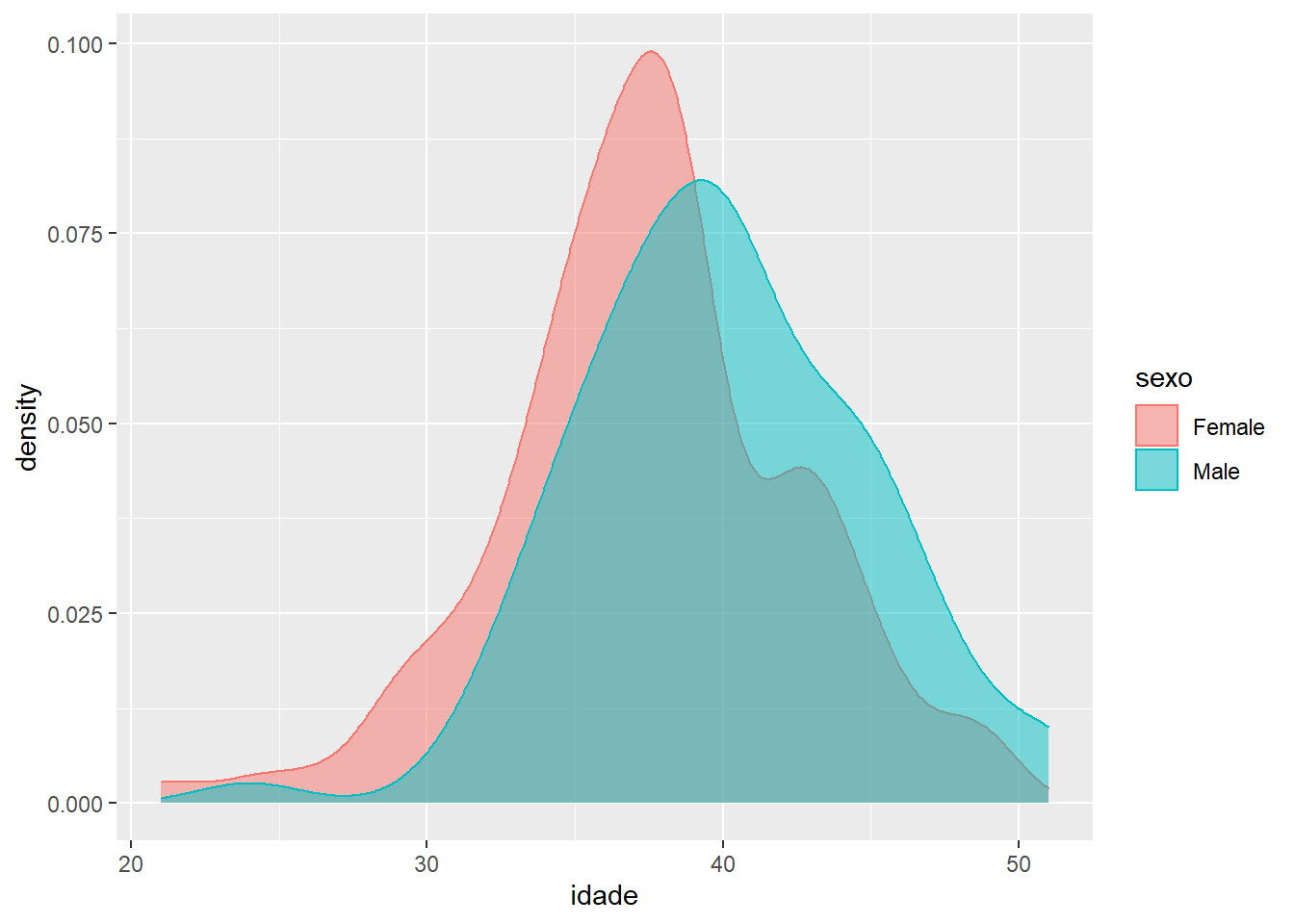
Que belezura de gráfico! A comparação de distribuições de uma variável dependente por uma variável binária (duas categorias) é uma das mais úteis em ciência, pois é exatamente a forma gráfica de testes de hipóteses. Qual grupo tem, na média, mais idade em Fakeland? Com os gráficos fica fácil responder
Curva de densidade ou boxplot?
Vamos repetir o gráfico acima, mas, em vez de separar as distribuições por sexo, vamos separar por uma variável com mais categorias: ‘educ’, que representa nível educacional mais alto obtido pelo indivíduo em Fakeland.
ggplot(fake, aes(x = idade, fill = educ, colour = educ)) +
geom_density(alpha = 0.5)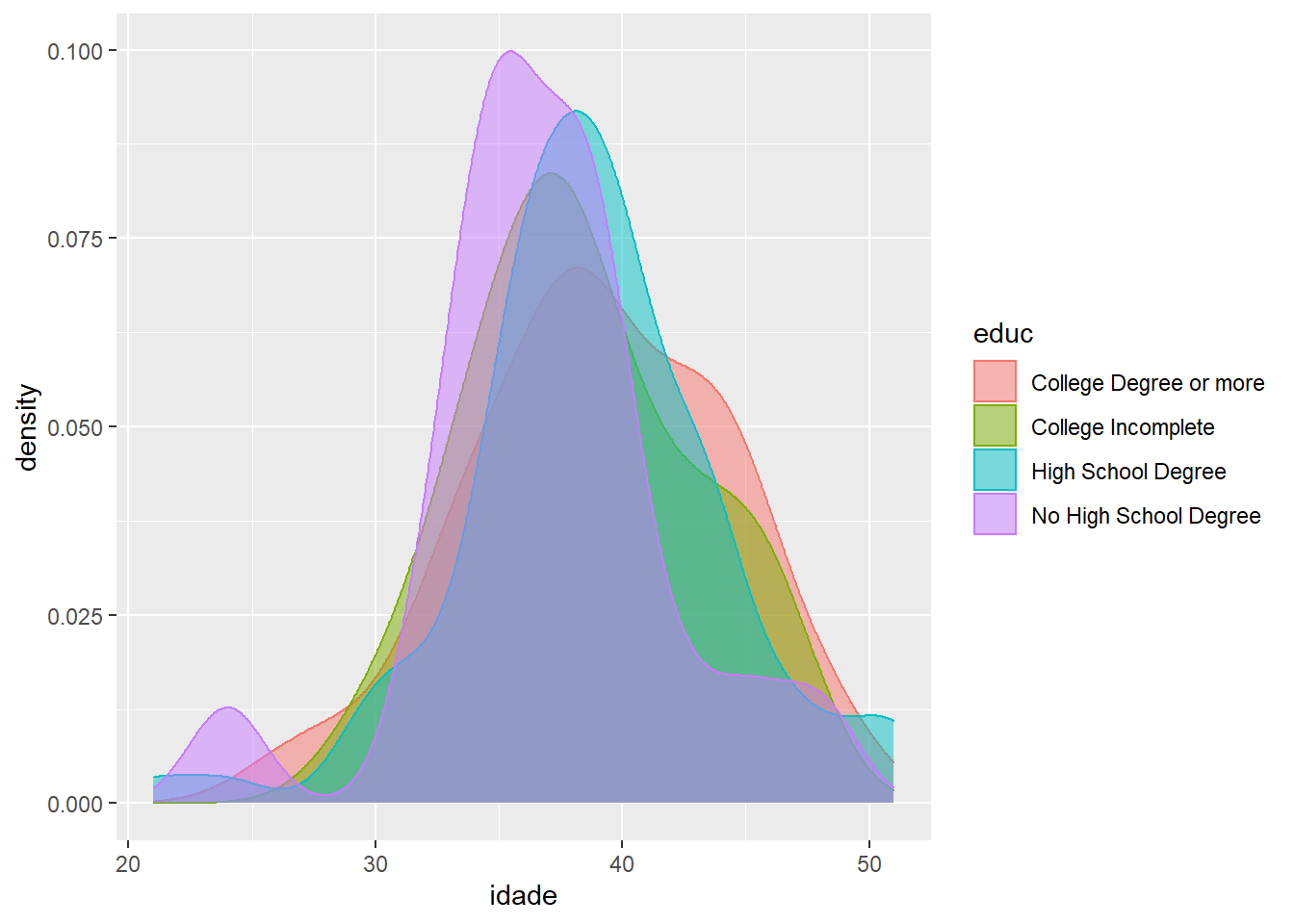
Dá par comparar as distribuições de idade por grupo? Certamente não. Podemos ter alguma ideia de que não há muita diferença, mas o gráfico é poluído demais.
Uma alternativa mais sintética, ou seja, que contém menos informações, para representar distribuições de variáveis numéricas é utilizar boxplot. Vamos ver um exemplo que serve de alternativa ao gráfico anterior.
Nota: na nova “aesthetics” temos agora “x” (eixo horizontal) e “y”, eixo vertical.
ggplot(fake, aes(x = educ, y = idade)) +
geom_boxplot()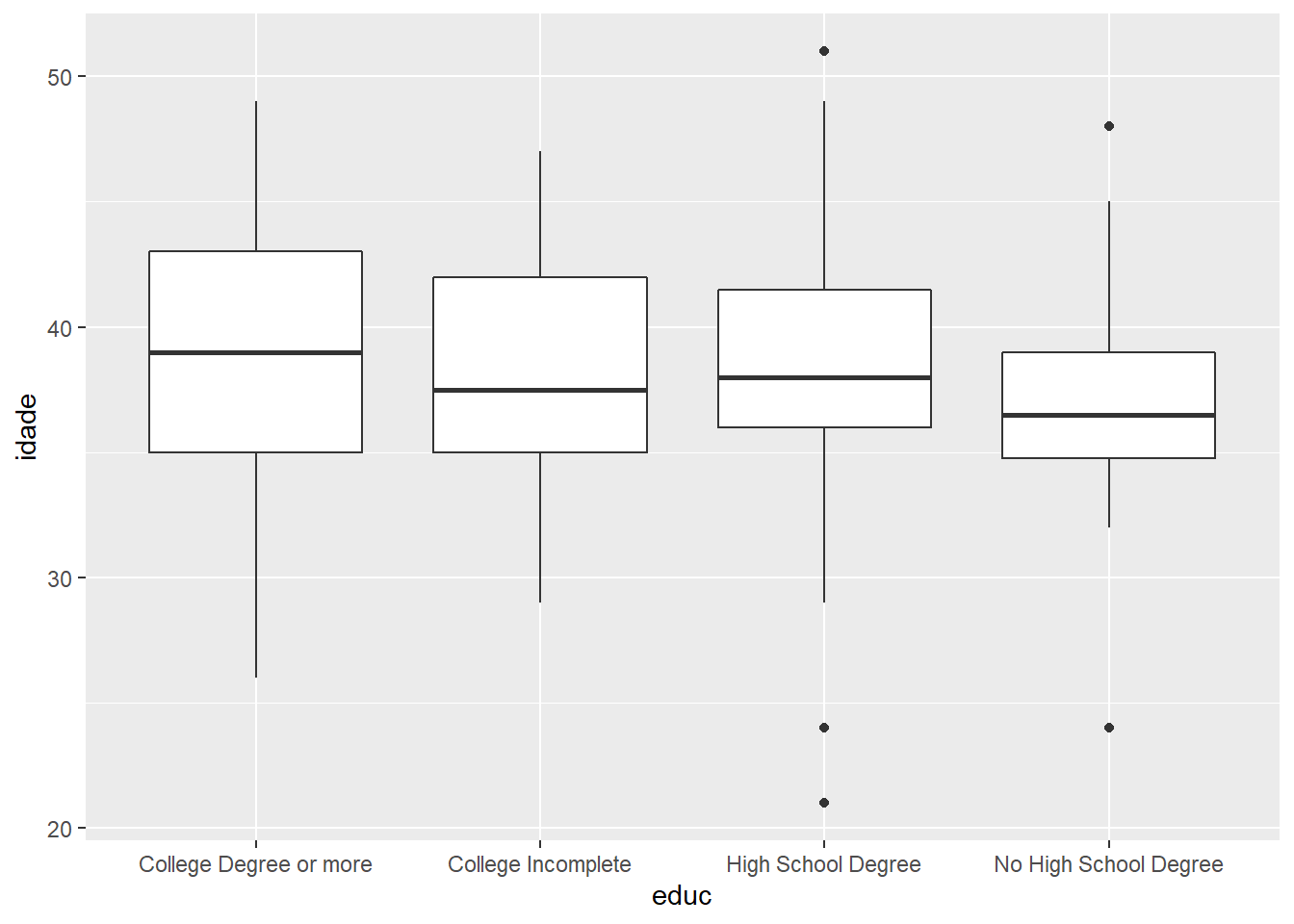
Importante: se você não tem familiaridade com boxplots, me peça uma rápida explicação.
Ainda que com perda de informação, conseguimos compara as distribuições de idade por nível educacional de forma bastante rápida. As médias são próximas e as distribuições mais à esqueda são ligeiramente mais concentradas em torno da média do que as distribuições mais à direita.
Para colocar um pouco de cor nos boxplots, podemos usar “fill” novamente:
ggplot(fake, aes(x = educ, y = idade, fill = educ)) +
geom_boxplot()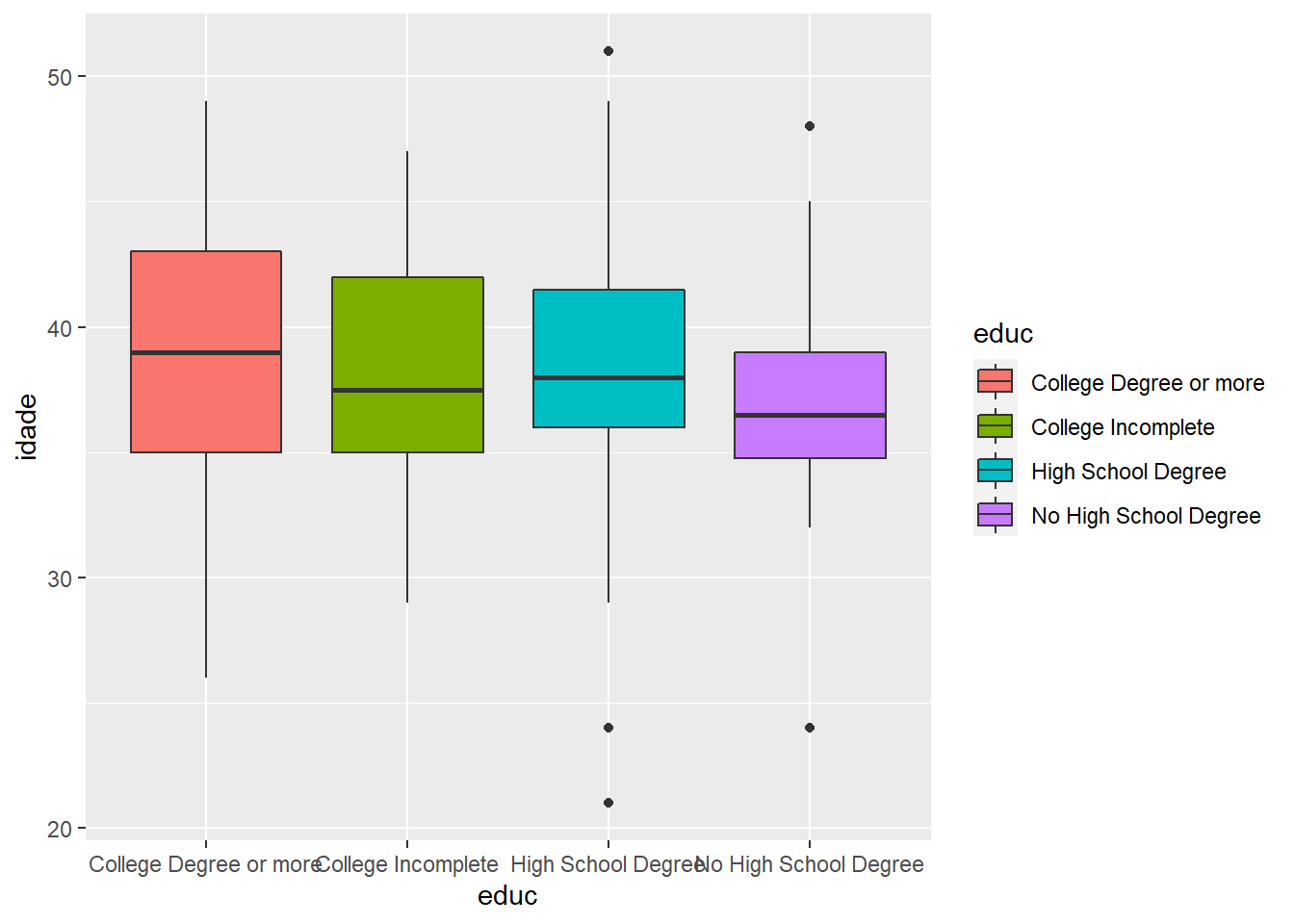
Gráfico de barras, para variáveis categóricas, e histogramas, curvas de densidade e boxplot são os melhores gráficos para explorarmos as distribuição de variáveis quando queremos conhecer os dados que recém coletamos ou obtemos.
Duas variáveis contínuas e gráfico de dispersão
Até agora trabalhamos com distribuições de uma única variável ou com a distribuição conjunta de uma variável contínua por outra discreta (em outras palavras, separados a distribuição de uma variável em várias a partir de um variável categórica).
Vamos ver agora como relacionar graficamente duas variáveis contínuas. O padrão é usarmos a geometria de gráfico de dispersão, que presenta cada par de informações como uma coordenada no espaço bidimensional. Vamos ver um exemplo com idade (eixo horizontal) e renda (eixo vertical):
ggplot(fake, aes(x = idade, y = renda)) +
geom_point()
Você consegue ler este gráfico? Cada ponto representa um indivíduo, ou seja, posiciona no espaço o par (idade, renda) daquela(e) indivíduo.
Note que há uma certa tendência nos dados: quanto mais velha a pessoa, maior sua renda. Podemos representar essa relação com modelos lineares e não lineares. A geometria geom_smooth cumpre esse papel.
Para utilizá-la, precisamos definir qual é o método (parâmetro “method”) de ajuste aos dados. O mais convencional é representar a relação entre as variáveis como reta. Veja o exemplo (ignore o parâmetro “se” por enquanto):
ggplot(fake, aes(x = idade, y = renda)) +
geom_point() +
geom_smooth(method = "lm", se = FALSE)## `geom_smooth()` using formula 'y ~ x'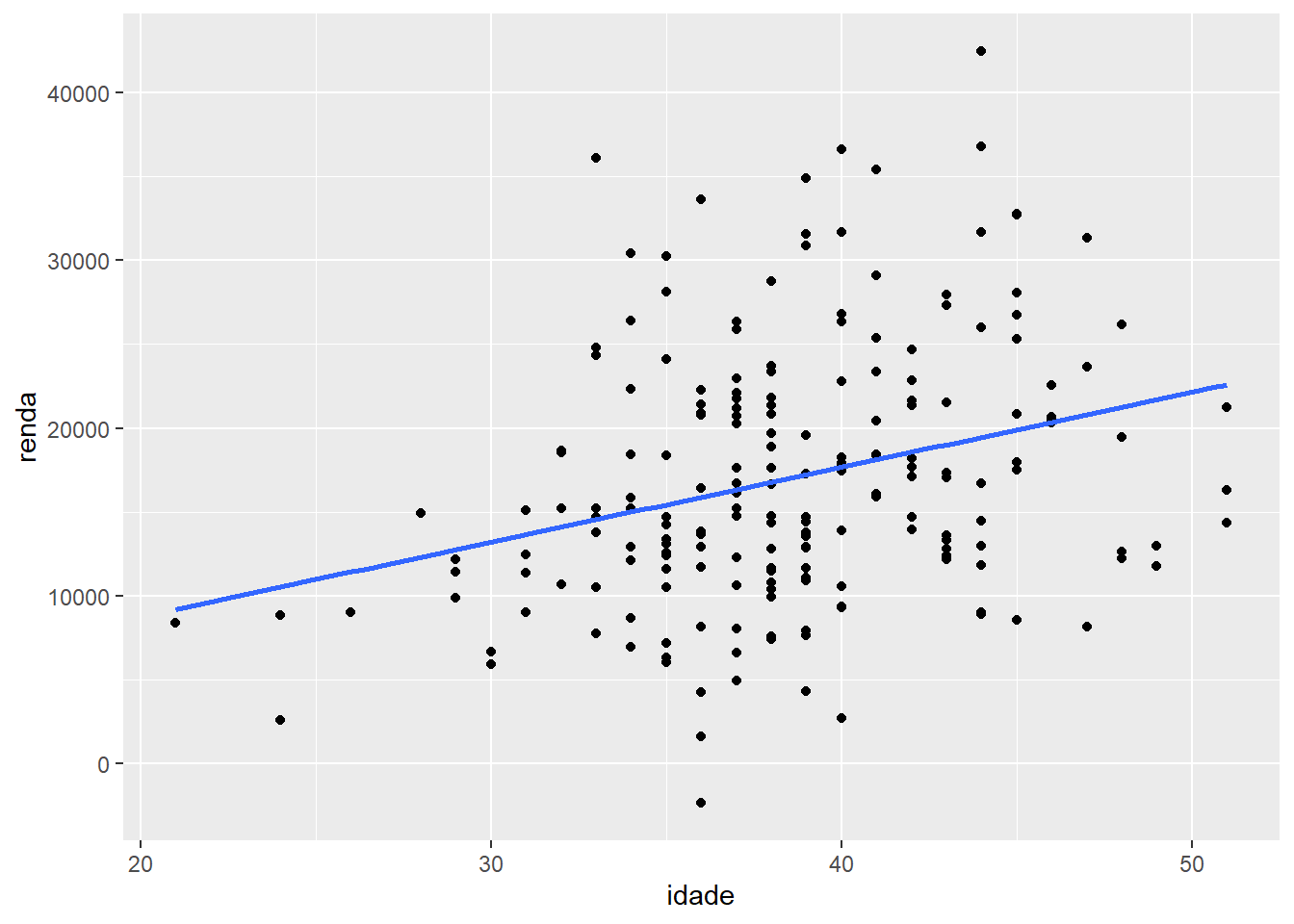
Legal, não? Se retirarmos o parâmetro “se”, ou voltarmos seu valor para o padrão “TRUE”, obteremos também o intervalo de confiança da reta que inserimos.
ggplot(fake, aes(x = idade, y = renda)) +
geom_point() +
geom_smooth(method = "lm")## `geom_smooth()` using formula 'y ~ x'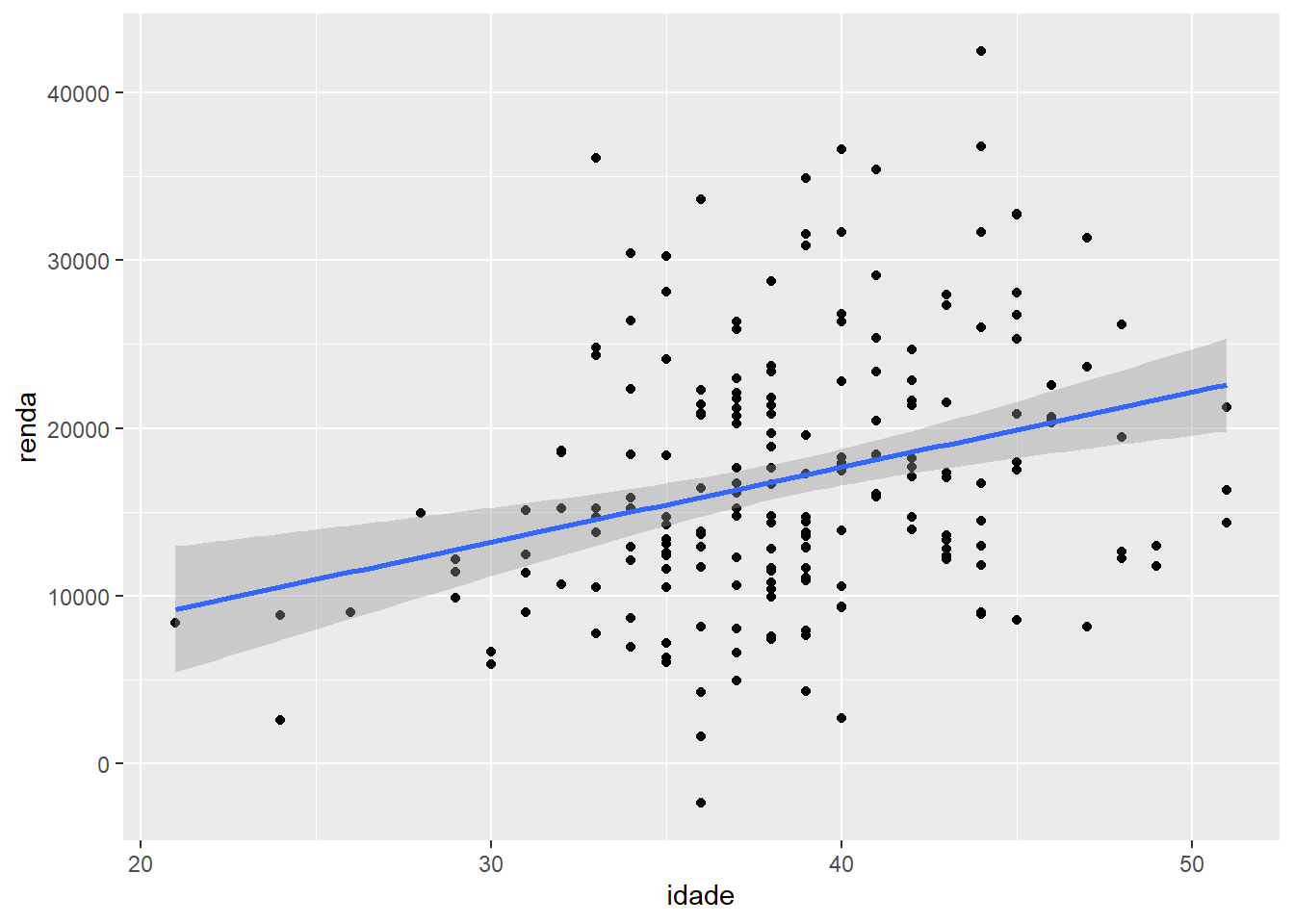
Modelos de regressão, linear ou não, estão bastante fora do escopo deste curso. Mas podemos falar sobre isso individualmente se você quiser. Tente apenas interpretar o resultado gráfico.
A alternativa não linear para representar a relação ao dados mais utilizada com essa geometria é o método “loess”. Veja o resultado:
ggplot(fake, aes(x = idade, y = renda)) +
geom_point() +
geom_smooth(method = "loess")## `geom_smooth()` using formula 'y ~ x'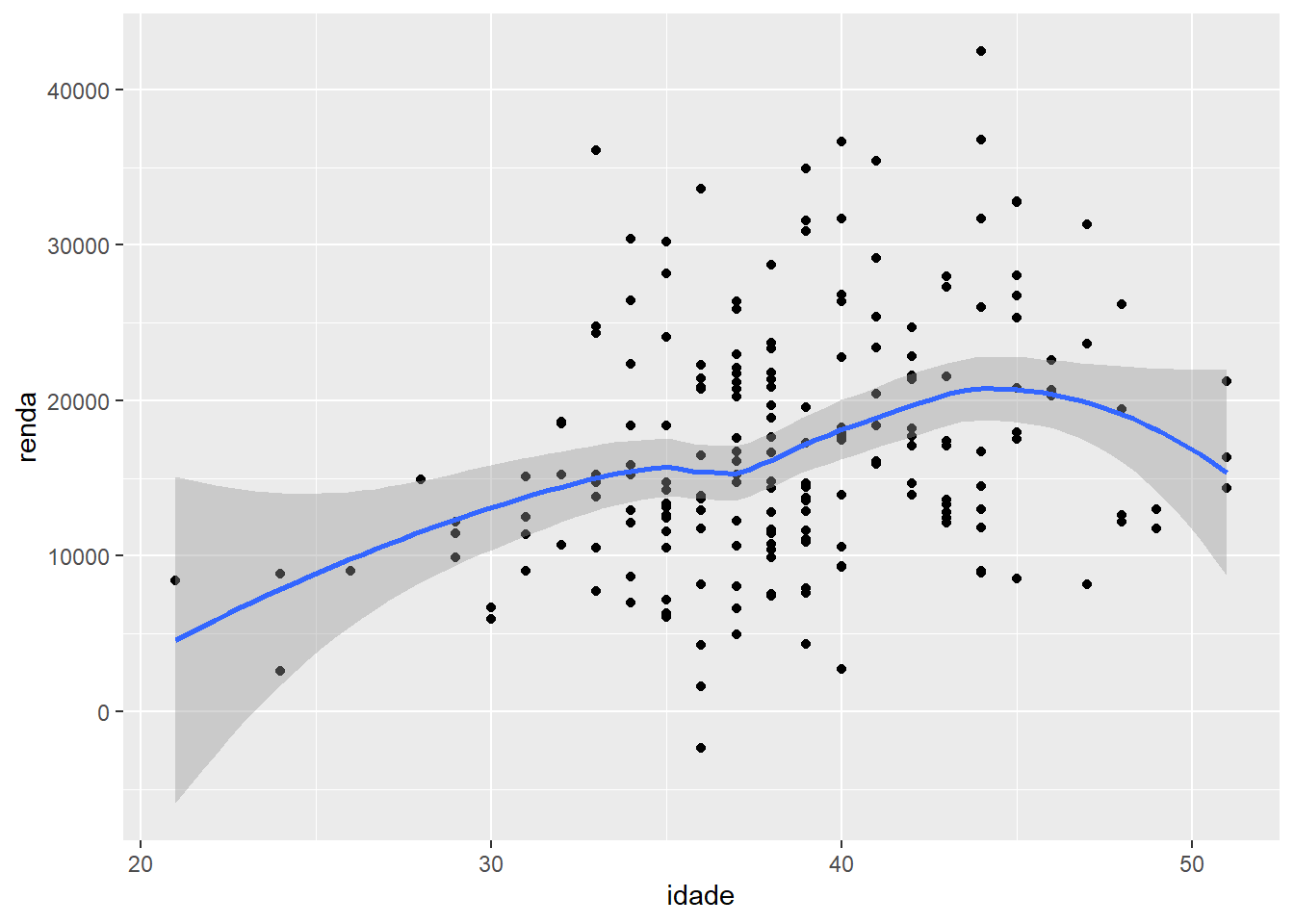
E se quisermos inserir informações de outras variáveis no gráfico? É possível?
Sim, é. Se, por exemplo, queremos representar uma terceira variável numérica, podemos colocá-la como o tamanho dos pontos (raio do círculo). Por exemplo, o número de filhos, variável que vai de 1 a 10 nos nossos dados, poderia ser adicionada da seguinte forma:
ggplot(fake, aes(x = idade, y = renda, size = filhos)) +
geom_point()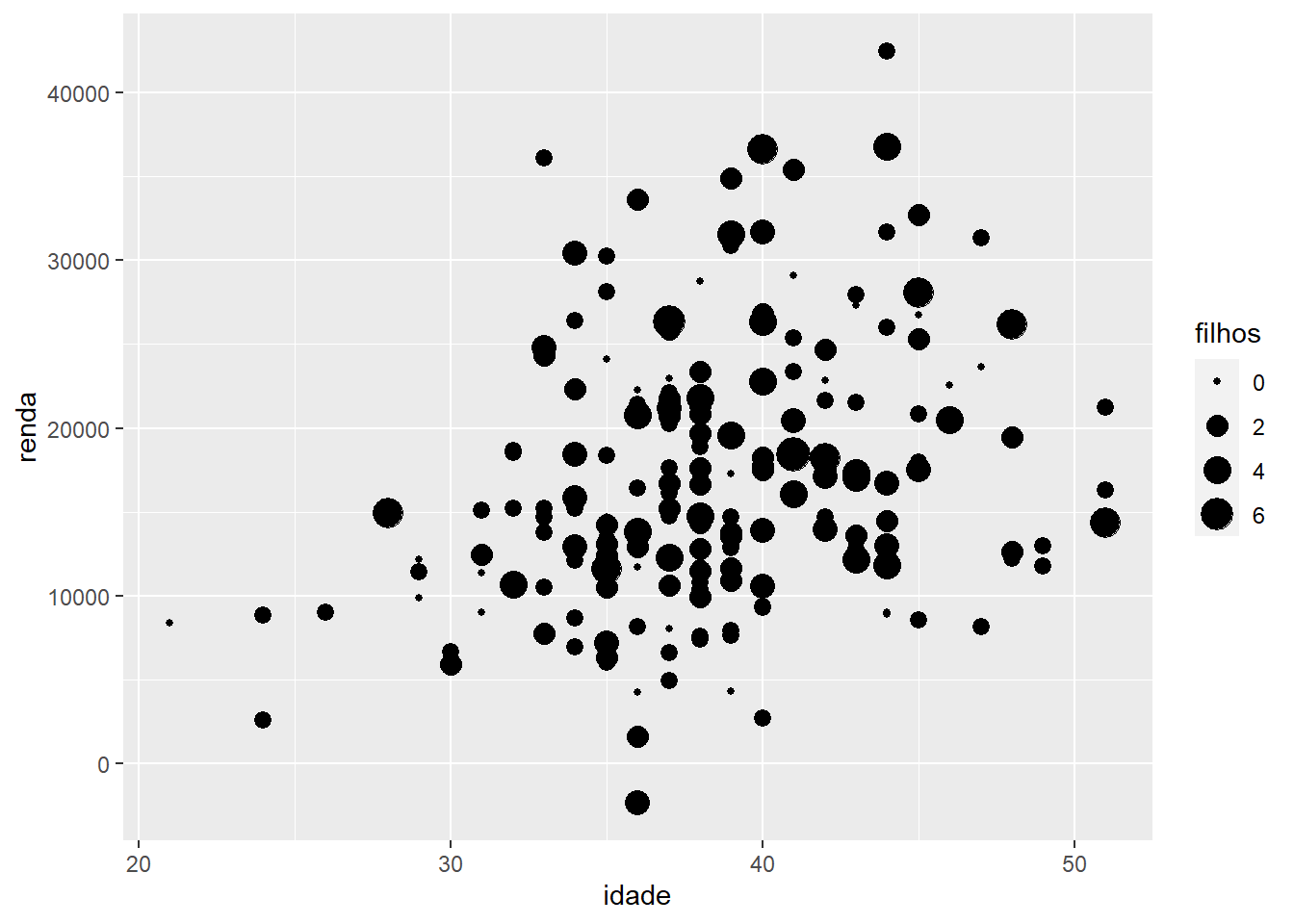
Se, em vez de alterar o tamanho dos pontos por uma variável numérica, quisermos alterar sua cor ou forma dos pontos com base em uma variável categória (sexo, por exemplo), fazemos, respectivamente:
ggplot(fake, aes(x = idade, y = renda, colour = sexo)) +
geom_point()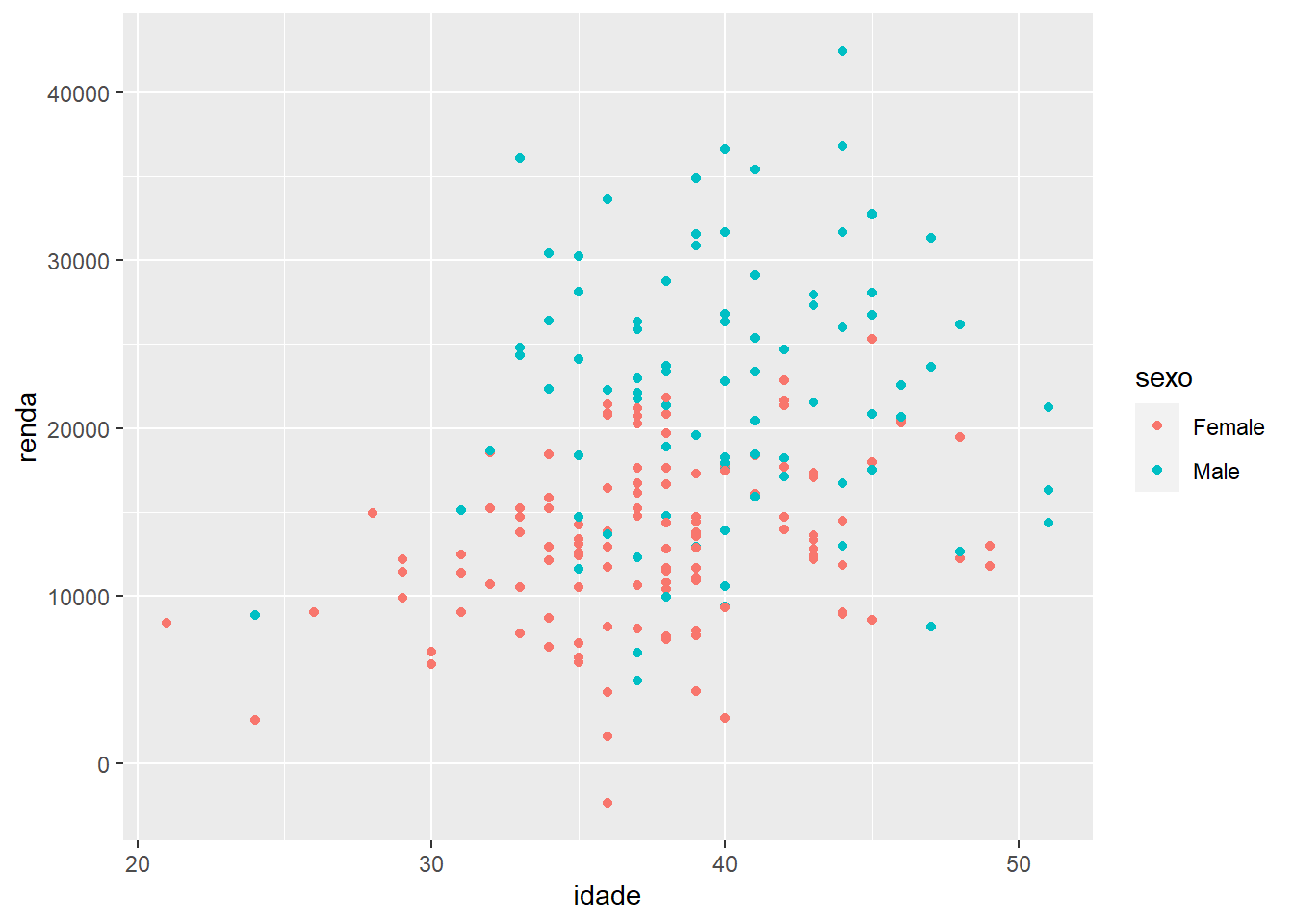
Ou:
ggplot(fake, aes(x = idade, y = renda, shape = sexo)) +
geom_point()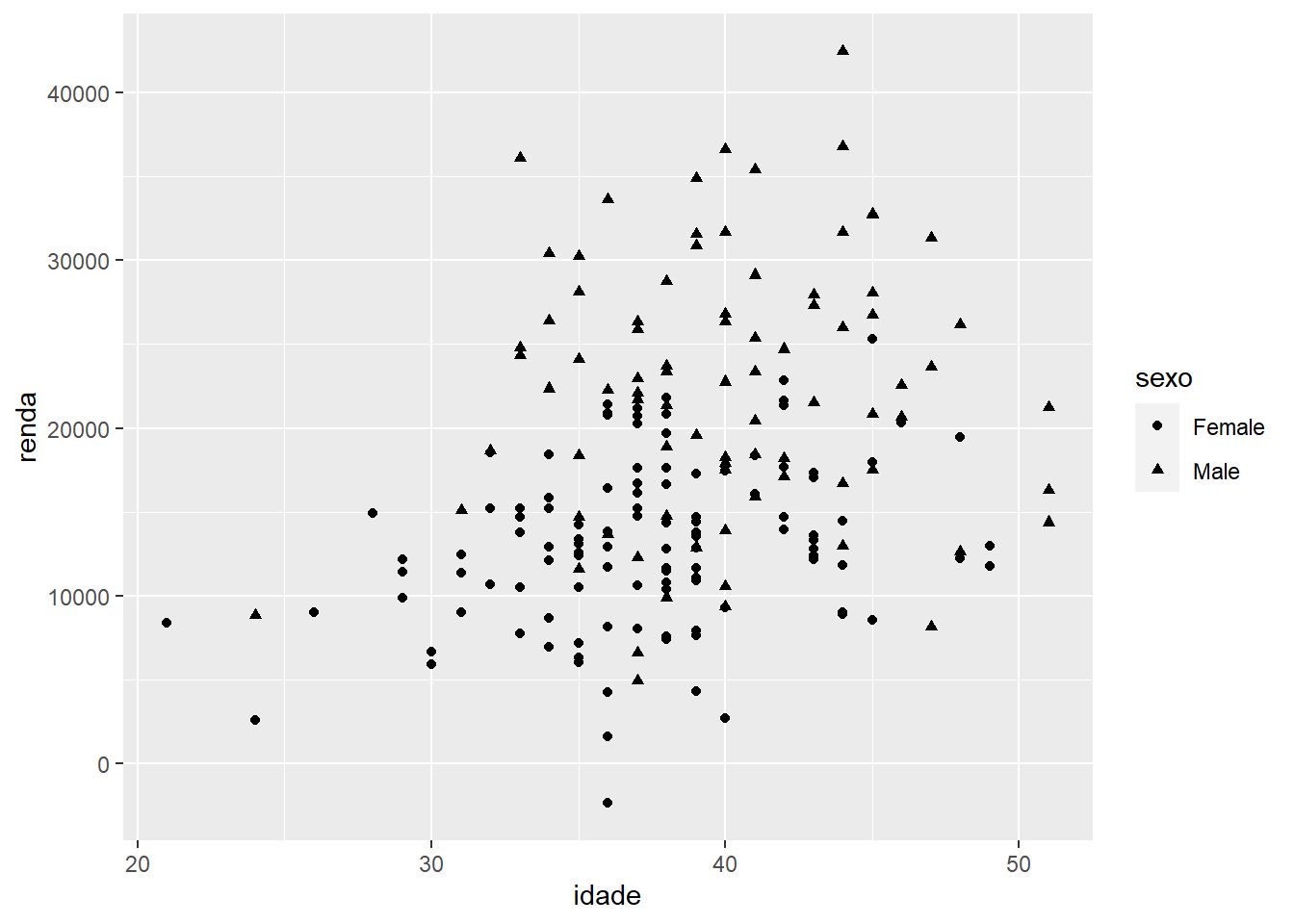
Nota: cada símbolo é representado por um número e você encontra facilmente na documentação a tabela de códigos dos diferentes símbolos.
Alterando simultaneamente cor e forma:
ggplot(fake, aes(x = idade, y = renda, colour = sexo, shape = sexo)) +
geom_point()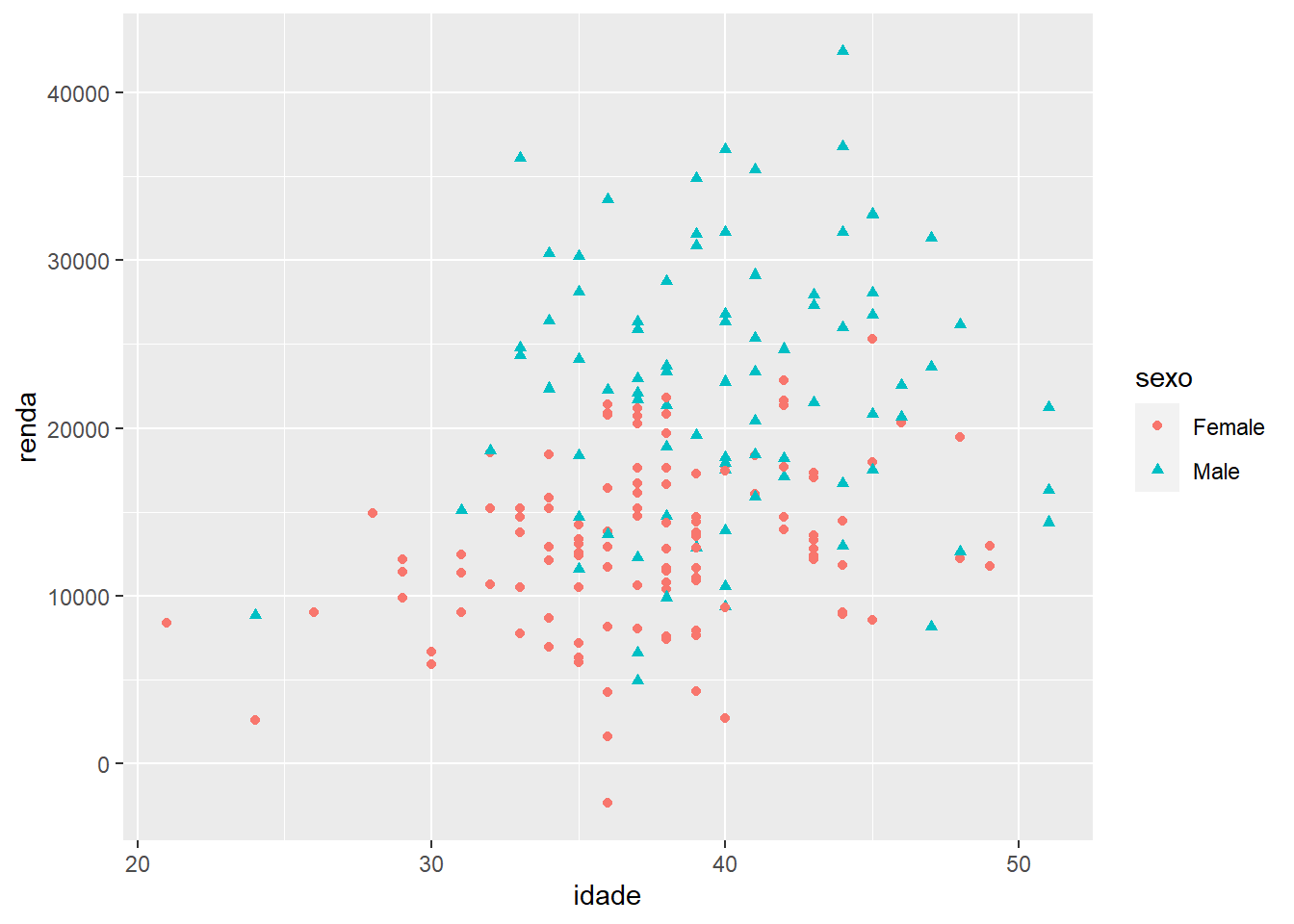
Adicionando uma reta de regressão para cada categoria de sexo:
ggplot(fake, aes(x = idade, y = renda, colour = sexo)) +
geom_point() +
geom_smooth(method = "lm", se = F)## `geom_smooth()` using formula 'y ~ x'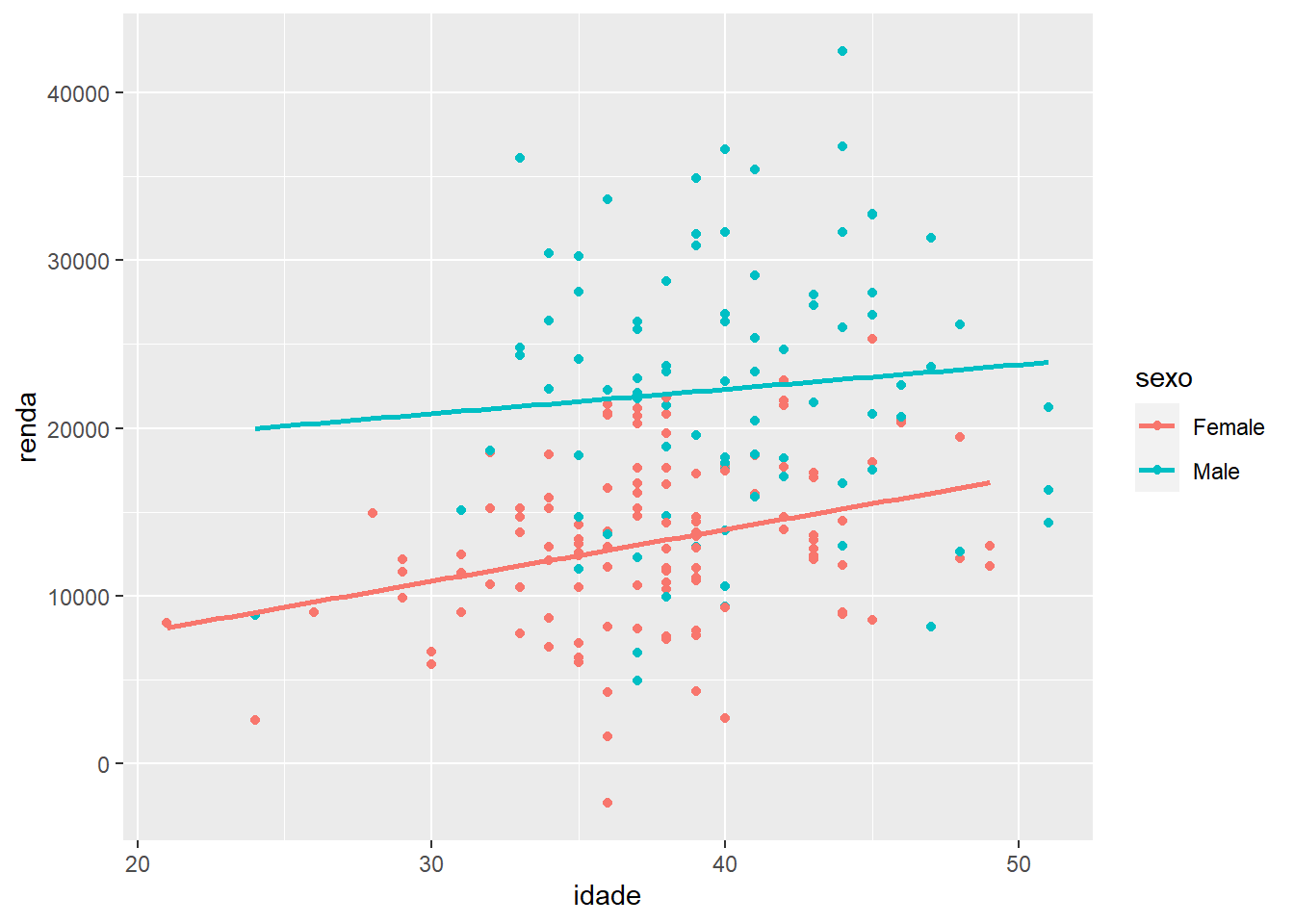
Lindo, não?
Aspectos não relacionados à geometria
Finalmente, podemos alterar diversos aspectos não relacionados aos dados, geometria e “aesthetics”. O procedimento para adicionar alterações em título, eixos, legenda, etc, é o mesmo que para adicionar novas geometrias. Vamos trabalhar com o último gráfico que produzimos fazendo pequenas modificações.
Em primeiro lugar, vamos adicionar um título ao gráfico:
ggplot(fake, aes(x = idade, y = renda, colour = sexo)) +
geom_point() +
geom_smooth(method = "lm") +
ggtitle("Renda por idade, separado por sexo")## `geom_smooth()` using formula 'y ~ x'
A seguir, vamos modificar os nomes dos rótulos dos eixos:
ggplot(fake, aes(x = idade, y = renda, colour = sexo)) +
geom_point() +
geom_smooth(method = "lm") +
ggtitle("Renda por idade, separado por sexo") +
xlab("Idade (em anos inteiros)") +
ylab("FM$ (Fake Money)")## `geom_smooth()` using formula 'y ~ x'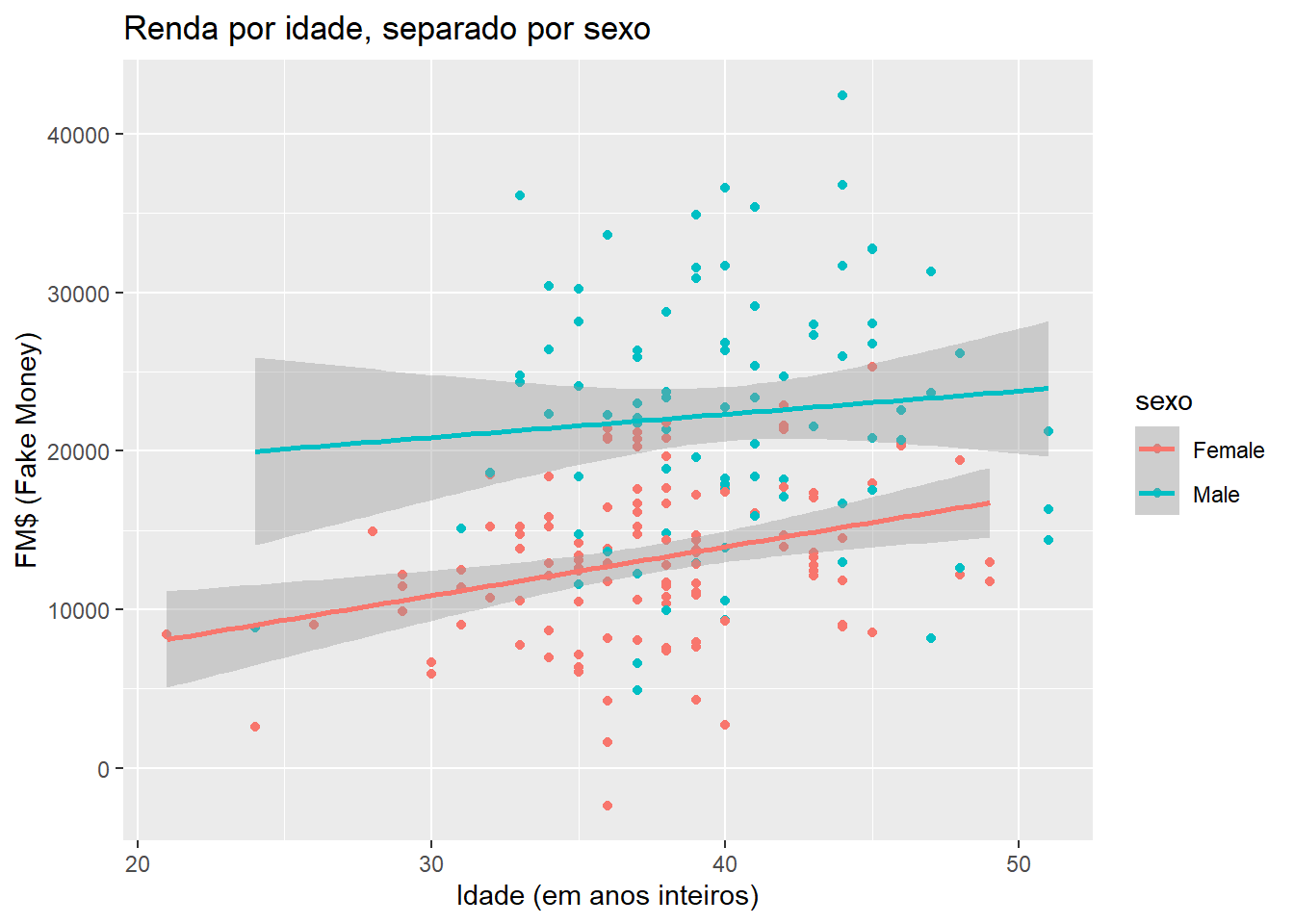
Também podemos modificar as legendas. Há um conjunto de comandos “scale”, que variam de acordo com o elemento da “aesthetics” que definem a legenda e com o tipo de variável, que podem ser usadas para tanto. No nosso caso, usamos uma variável discreta (sexo) como “colour”, e, por tanto, precisamos usar a função scale_colour_discrete:
ggplot(fake, aes(x = idade, y = renda, colour = sexo)) +
geom_point() +
geom_smooth(method = "lm") +
ggtitle("Renda por idade, separado por sexo") +
xlab("Idade (em anos inteiros)") +
ylab("FM$ (Fake Money)") +
scale_colour_discrete(name="Sexo",
breaks=c("Female", "Male"),
labels=c("Mulher", "Homem"))## `geom_smooth()` using formula 'y ~ x'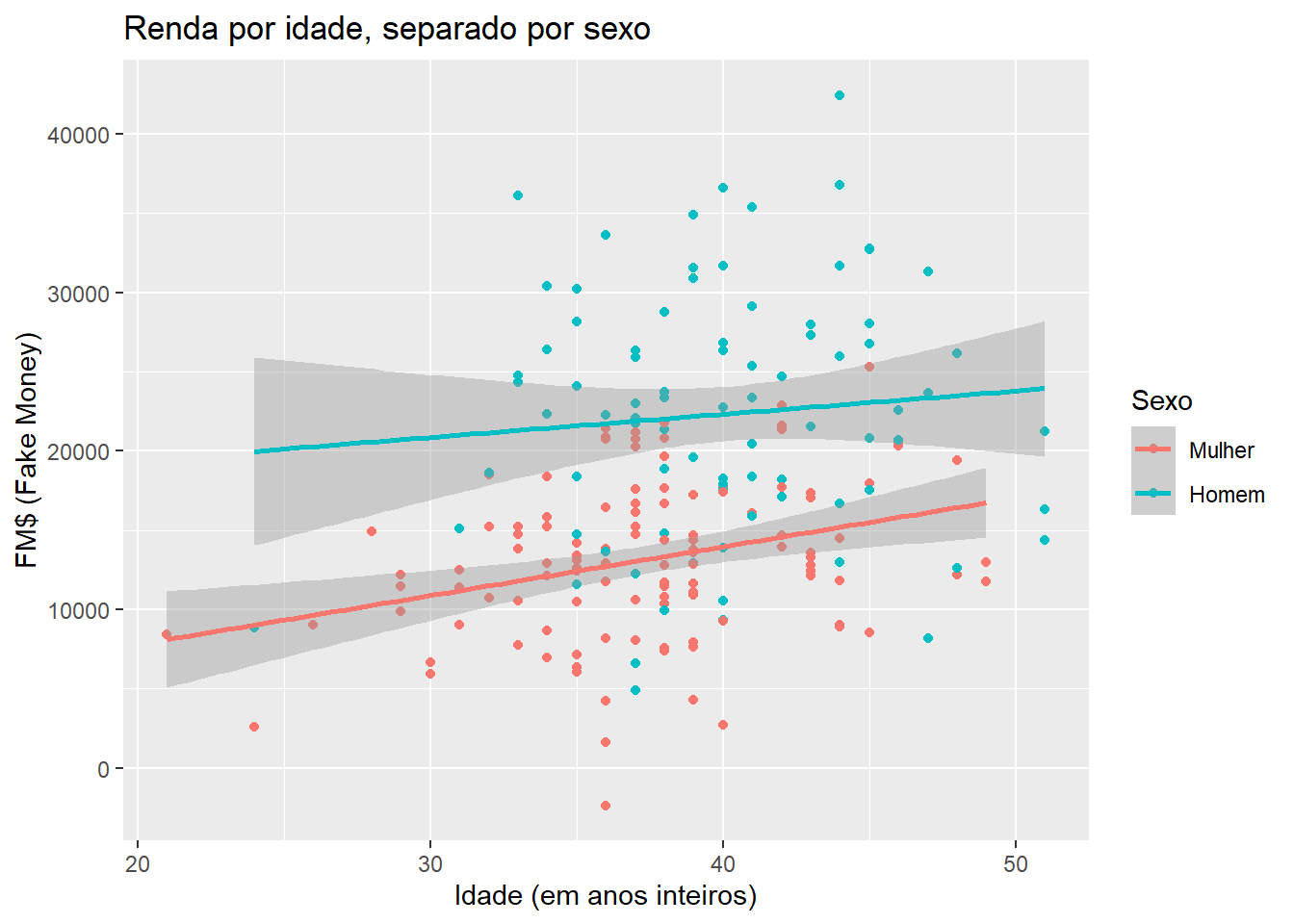
Excelente!
Vamos complicar um pouco mais. Vamos supor que queremos separar agora nossos dados em múltiplos gráficos diferentes, um para cada nível de educação. Como fazer isso? Com face_grid ou facet_wrap. Veja um exemplo com o último:
ggplot(fake, aes(x = idade, y = renda, colour = sexo)) +
geom_point() +
geom_smooth(method = "lm") +
ggtitle("Renda por idade, separado por sexo") +
xlab("Idade (em anos inteiros)") +
ylab("FM$ (Fake Money)") +
scale_colour_discrete(name = "Sexo",
breaks = c("Female", "Male"),
labels = c("Mulher", "Homem")) +
facet_wrap( ~ educ, ncol = 2)## `geom_smooth()` using formula 'y ~ x'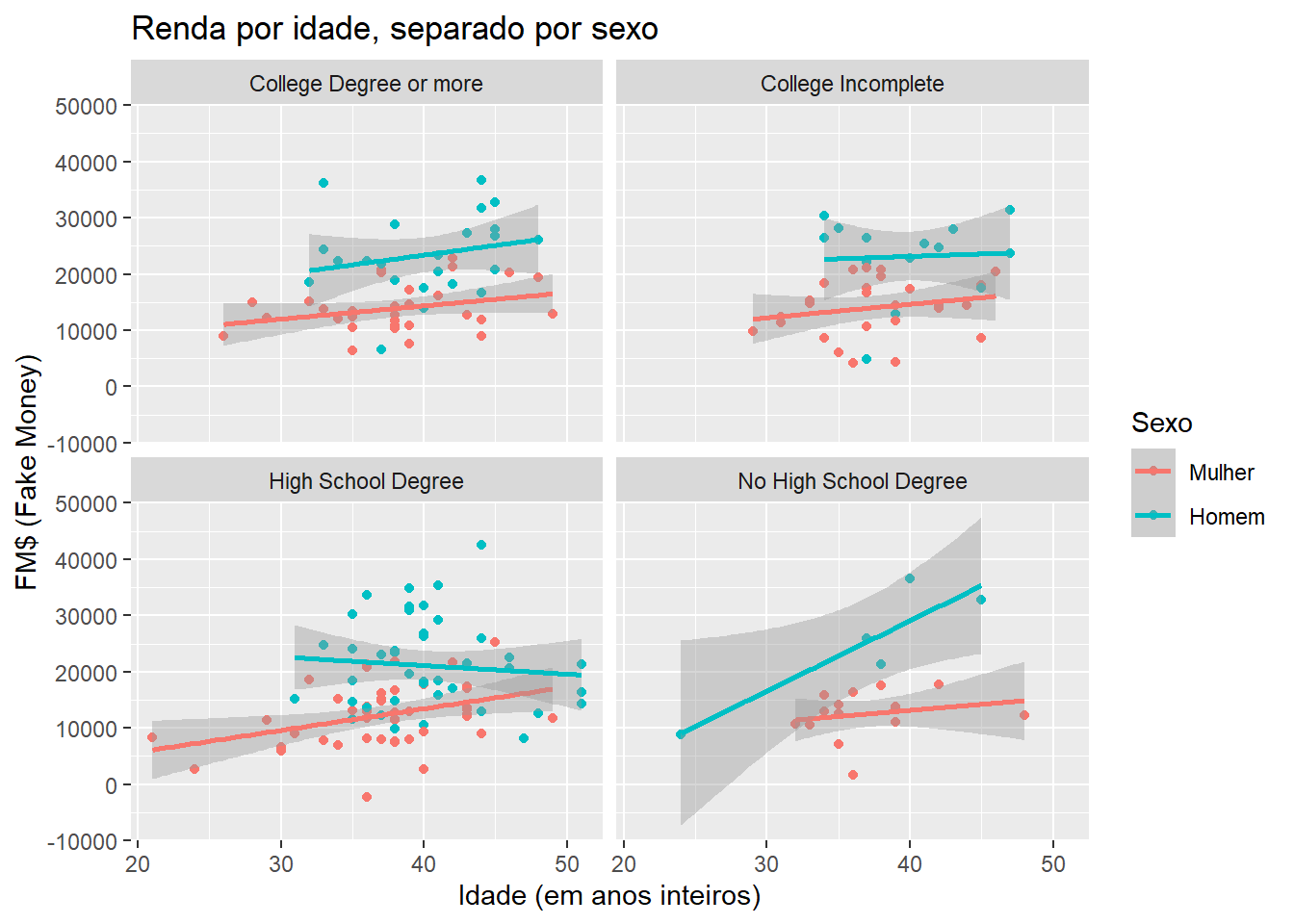
Ufa! Quanta coisa em um só gráfico!